随着计算任务复杂度的不断提高,处理深度嵌套数据结构已成为软件开发中的重要挑战。传统基于栈的递归遍历方法在面对大量嵌套层级时,往往出现栈空间耗尽、程序崩溃等诸多问题。为了突破这一瓶颈,无栈遍历技术应运而生,尤其在2018年由Dyalog团队针对APL语言的实现中展现出令人瞩目的性能提升。无栈遍历不仅解决了深度递归导致的栈溢出风险,同时极大地提升了数组遍历和元素提取的效率,成为数据处理领域的一项里程碑式技术。无栈遍历的核心问题在于如何在不依赖传统调用栈的情况下,维护遍历过程中的回溯信息。传统递归函数依靠程序栈保存每一层的执行状态和变量信息,从而实现对嵌套结构的深层访问。
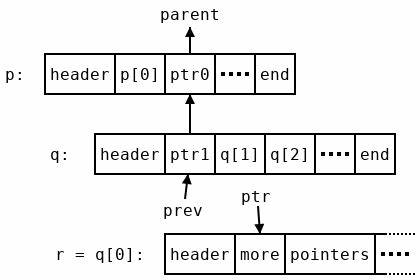
然而,程序栈的尺寸天生有限,深度几千层或更多的数组结构会迅速耗尽这一资源,导致系统错误。面对这一限制,无栈遍历创新性地利用了数组内部指针的空闲位,实现了状态信息的嵌入式保存。具体来说,每个数组在内存中表现为一段“口袋”区域,包含头信息和指向子数组的指针集合。由于指针的内存地址需对齐,其最低若干位通常为零,因此这部分位可以被用作存储标志位和控制信息,而不会破坏指针指向有效的内存。此外,遍历时针对每一层数组所需的父节点状态信息,通过巧妙地反转指针链条,建立起一条回溯路径。这种做法允许遍历过程从任意深度的子节点一步步“倒退”到父节点,而无需额外的内存堆栈支持。
为了控制何时终止对每个数组的遍历,无栈遍历利用指针中嵌入的位标记做结束信号,从而避免了越界访问和段错误风险。通过这一系列创新,算法将必要的状态管理完全内嵌于数据结构自身,大幅降低了额外内存分配的频率与复杂度,避免了传统遍历方案中繁重的内存操作开销。相比于原先Dyalog中通用的遍历机制,新的无栈遍历方法专注于特定场景——即对嵌套数组中“叶子”节点的处理,简化了操作流程,去除了不必要的通用性开销,从而实现了整体性能的显著提升。实测数据显示,在处理深度数千层的嵌套数组时,无栈遍历相较于旧版本约有6倍以上的速度提升。在多数日常应用场景中,小规模嵌套数组的处理速度也提高了2倍以上。尤其在元素较小且嵌套层数较深时,无栈遍历优势尤为明显。
此技术不仅提升了数组拆包(enlist)操作效率,同时还被广泛用于多种函数的底层实现中,如哈希计算和有序查找等,为APL语言乃至更广泛的函数式编程生态带来性能上的优势。不仅如此,无栈遍历的实现对内存管理策略提出了更高的要求。由于算法会在遍历过程中直接修改数组指针中的标志位,Workspace的状态在遍历过程中处于非稳定状态,因此不能在遍历期间进行动态内存分配或涉及内存移动操作。对此,团队制定了严格的使用条件,确保所需内存于遍历开始前预先分配完毕,避免了期间内存碎片整理带来的干扰。这种限制虽然带来一定使用上的复杂性,但对于频繁且性能敏感的遍历操作来说,权衡得失极为合理。无栈遍历技术还巧妙利用嵌套数组中形状信息的存储格式,通过对形状及区域字段加以标记,实现了对回溯终点的辨识。
不同场景下,算法采用多种区分标识确保准确判别遍历终止条件,进而保证遍历的健壮性和准确性。一些边缘情况如空数组或仅含原型的“口袋”结构也被涵盖,使得算法具备较强的通用性和适应性。技术社区对无栈遍历给予了高度评价,称其为现代内存管理和数据结构遍历设计中的典范。由于其结构高度依赖于底层指针操作,对实现者的理解和编码能力提出了较高门槛,但带来的性能收益以及避免系统崩溃风险的稳定性优势使其成为值得推广的先进方法。面向未来,无栈遍历技术的思想和方法论同样具有广泛的参考价值。对其他编程语言或系统架构设计者而言,如何减少递归调用对系统栈的依赖、提升深度嵌套数据结构访问的效率,都可从无栈遍历中找到灵感。
随着硬件设计和软件需求的变化,类似嵌入式状态管理的策略或将成为主流。总结而言,无栈遍历作为一种创新的深度嵌套数据结构处理技术,突破了传统递归遍历的内存限制,通过巧妙利用指针对齐空位和指针反转,实现了高效、安全且稳定的遍历性能。其在Dyalog APL语言中的应用充分证明了该技术的实用性和优越性。对于开发者而言,理解并掌握无栈遍历的设计思想不仅有助于优化当前项目性能,更可为解决复杂数据访问场景提供宝贵的方法论支持。未来,随着技术的不断演进,无栈遍历及其衍生技术必将在软件开发领域发挥更大影响,助力实现更加高效和稳定的计算体验。