人工智能的迅速演进正在深刻改变整个科技行业和应用开发的格局。尤其是大型语言模型(LLM)及其他复杂AI工作负载,对计算资源的需求和运行模式与传统的无服务器计算存在显著差异。传统无服务器计算设计初衷主要面向快速、无状态且短暂的Web应用请求处理,处理单个请求通常耗时毫秒级别。然而,AI工作负载尤其是与大型语言模型的交互,通常涉及长时间的计算过程和不规则的激活周期,这就要求一种全新的计算模式来高效支撑。Fluid计算正是在此背景下应运而生,它旨在突破传统无服务器架构的限制,为AI工作负载提供量身定制的解决方案。 在传统无服务器环境下,每一次用户请求通常都会激活一个新的函数实例,这种设计对于短暂且独立的请求响应极为高效。
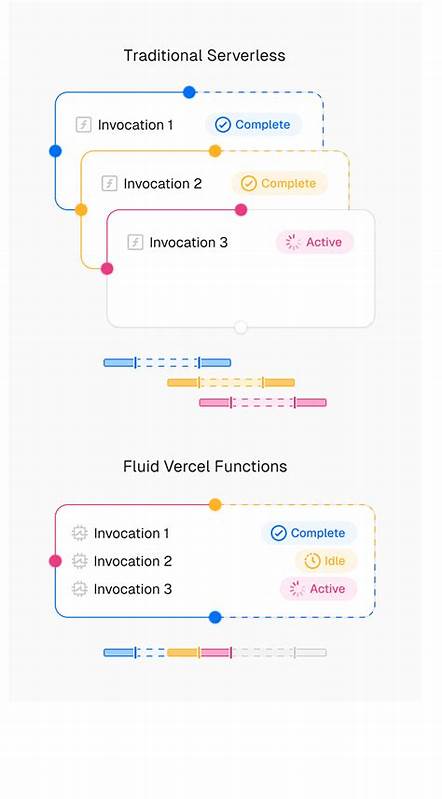
然而,当面对大型语言模型时,函数往往需要经历初始化、请求发送、等待响应和结果返回的全过程,这个过程可能持续数秒甚至数分钟。更值得注意的是,在等待大型模型响应的过程中,函数实例虽然处于空闲状态,但依然会持续消耗计算资源,导致大量被计费而未被充分利用的“闲置计算”。此外,若函数在等待回复期间超时,则必须重新启动新的实例处理流式数据,进一步增加了资源浪费和成本负担。 Fluid计算通过智能复用现有计算资源,有效减少不必要的函数启动,从根本上提升资源的利用效率。不同于传统的“一请求一实例”模式,Fluid计算优先在现有活跃实例中处理新的AI推理请求,实现了“多对一”的计算共享。这种动态调度机制避免了频繁的冷启动和额外的资源分配,使得AI应用能够连续流畅地响应用户请求,同时大幅降低成本开销。
通过Fluid计算,一个实例可以同时处理多个AI推理任务,基于动态调整的资源分配,确保各项工作负载均能得到充分支持,最大化资源使用率。 此外,Fluid计算还注重性能与地域优化,智能地将计算资源部署在与数据所在地接近的区域,显著提升响应速度和处理一致性。对于需要大量数据访问和运算密集型的AI应用,这种优化策略不仅保证了用户体验,更提升了整体系统的稳定性和可扩展性。无论是在应对突发访问压力,还是持续的后台推理任务,Fluid计算都能灵活调整资源,确保AI应用始终高效稳定运行。 安全性方面,Fluid计算架构内置多层防护机制,强化AI工作负载的防护能力。借助边缘安全技术,如Vercel防火墙,所有请求都会经过最近的接入点过滤,阻挡常见的应用层攻击和恶意流量。
实例本身通过安全的持久TCP隧道与函数路由器通信,避免直接暴露于互联网,增加了系统的隔离性和抗攻击能力。多可用区甚至多区域的自动故障切换机制确保了任务的高可用性和容错能力,使得用户业务即便在遇到局部故障时也能保持不中断。 Fluid计算显著改变了无服务器计算的资源生命周期管理。传统模式中,计算资源的生命周期假设函数会快速完成任务并释放资源,而Fluid计算则支持长时间的任务存在和多任务并行处理,符合AI工作负载的连续性和复杂执行需求。这不仅促进了更高效的资源调度,还带来了更为经济的成本结构,有效降低了用户在大规模AI部署方面的投入门槛。 AI的发展推动了软件架构的革新,Fluid计算成为连接传统无服务器与AI计算需求之间的桥梁。
其智能复用、动态调度、区域优化及严密的安全防护,为AI应用构建了理想的运行环境。开发者无需再为频繁的资源启动和闲置成本担忧,能够专注于构建更复杂、更智能的功能,提升产品的竞争力。 同时,Fluid计算为企业提供了灵活且可扩展的基础设施保障,支持快速迭代与上线AI驱动的业务创新。无论是智能客服、推荐系统、实时数据分析还是自然语言处理应用,Fluid计算都能以更低的延迟、更高的吞吐量保障服务的稳定运行,推动各行业的数字化转型进程。 总结来看,Fluid计算不仅仅是对无服务器计算模型的优化升级,更是针对AI时代计算需求的深度定制。它以高效资源利用为核心,突破了传统架构的局限,助力AI应用实现规模化、低成本和高安全的运行。
随着AI技术的不断普及和应用场景的拓展,Fluid计算将成为支撑未来智能计算平台不可或缺的重要基石。拥抱Fluid计算意味着迎接AI计算的高速发展,赋能创新应用,开启智能时代的无限可能。