引言 随着移动设备与物联网的普及,海量 GPS 轨迹数据成为许多业务的核心资源。然而原始 GPS 数据通常噪声较大,存在卫星漂移、多路径反射及设备报告精度不一等问题。若直接用于分析或可视化,轨迹会出现抖动、跳跃和异常点,影响里程估算、行为识别及路径匹配的可靠性。卡尔曼滤波器(Kalman Filter)是一种成熟且高效的递归估计方法,擅长在带噪测量中恢复系统真实状态。将卡尔曼滤波直接内嵌到数据库中,能够消除额外的数据管道,使平滑后的结果可立即通过 SQL 查询访问,从而简化架构并提升分析效率。 卡尔曼滤波基础回顾 卡尔曼滤波器用于从带噪观测值中估计动态系统的状态,例如位置与速度。
核心在于在预测步骤中依据运动模型将状态向前投影,在更新步骤中用新观测进行校正。关键要素包括状态向量、过程噪声协方差矩阵、测量噪声协方差矩阵与滤波器增益。通过不断迭代,滤波器会对不确定性进行追踪,从而在有噪声的 GPS 序列中产生平滑且物理上合理的轨迹估计。实际应用中可以引入设备报告的精度指标(如 HDOP)作为测量噪声的一部分,以使更新步骤更灵活地反映观测质量。 为何在 Postgres 中实现卡尔曼滤波 传统上,卡尔曼滤波多在 Python、MATLAB 或流式处理框架中实现并在数据库之外运行。但将滤波器移至 PostgreSQL 有几项显著优势。
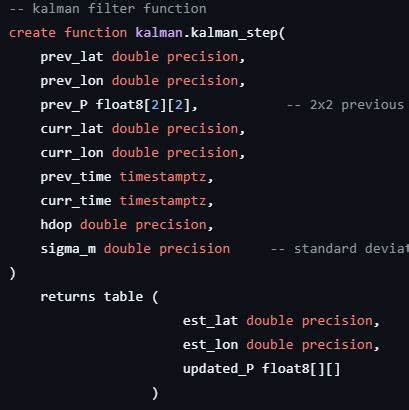
首先,减少数据导出与导入的复杂度与延迟,简化运维;其次,充分利用数据库的事务性、权限与索引能力,可以在查询层面直接得到平滑后的轨迹,便于联表分析与报表生成;最后,当数据量达到亿级或更高时,数据库内部的批处理与分布式执行(或借助 Neon 等 serverless 平台的弹性资源)能更经济地完成大规模离线重处理。 实现挑战与设计要点 在关系型数据库中实现递归滤波面临三大挑战:状态管理、转换函数与序列化顺序。卡尔曼滤波需要在每一步保存估计状态与其协方差矩阵。实现方式可以是为每个设备在数据库中维护一张状态表,包含最新估计与协方差,便于在线插入时更新;对于离线批处理,则需要在查询执行中按时间顺序传递状态。还需要一个用户定义函数来接受上一步状态与当前观测,并返回新的状态。最后,必须保证按时间戳严格排序地处理样本,滤波的递归性质对顺序极为敏感。
架构示例与模式 一个实用的设计是使用两个核心表:positions 用于存储原始 GPS 样本和过滤后的估计点;devices 用于存储每个设备的当前滤波状态及协方差矩阵。主要过滤逻辑封装成 SQL 可调用的函数,例如名为 kalman_step 的函数负责单步预测与更新,而 kalman_upsert_position 则在插入新观测时调用 kalman_step 并同时更新 devices 表的状态。这种模式适合在线过滤场景,保证随插入操作即时产生平滑结果,但会增加插入延迟。 在线过滤与离线过滤的取舍 在线过滤的优点是实时性:每次新样本入库时即可更新平滑轨迹,适合需要即时决策或实时地图显示的场景。缺点是额外的每次更新开销,会降低吞吐量并增加延迟。离线过滤则在历史数据上批量运行,允许更高效的资源利用与更快的吞吐量,且便于在滤波参数或模型调整后一次性重算整个轨迹库。
工程实践中常将在线与离线结合:在线提供近实时的平滑结果,离线周期性重跑以获得更精确或应用新模型后的结果。 在 SQL 中实现序列化迭代的两种主流方法 递归公共表表达式(CTE)是最直观的方法,可按时间顺序逐条传递状态并生成完整的历史滤波轨迹,便于调试与验证。但是递归 CTE 在大规模数据上往往性能不足。作为替代,自定义聚合函数可以在聚合过程中隐式维护状态并连续应用 kalman_step,从而在编码层面更接近 SQL 的批量处理模型。基准测试显示,对于离线批处理,自定义聚合在吞吐量上明显优于递归 CTE,而递归 CTE 更适合小规模或需要逐步检查的场景。 性能基准与实践数据 在多人与单机测试中可以观察到明显的差异。
在线在插入时应用滤波会将吞吐量下降大约 35% 到 40%,平均延迟从约 8.5 ms 增加到约 13.6 ms。在离线测试方面,递归方法与自定义聚合差别显著:递归方法在同一测试设置下的每秒事务数远低于基于自定义聚合的实现。基准结果表明,如果需要高吞吐量的离线重处理,优先选择自定义聚合能够带来更好的性能表现。 实现细节与函数设计要点 在实现 kalman_step 时,建议以低层语言或 PL/pgSQL 明确地表示状态更新逻辑:先做预测步骤,基于时间差与运动模型更新状态与预测协方差;然后根据测量噪声(可从观测中的 HDOP 或设备上报的精度字段推算)进行更新,计算滤波增益并得到最终估计与协方差。若观测包含速度或航向等信息,也可在状态向量中引入速度分量以改善预测能力。务必为协方差矩阵的数值稳定性做保护,例如限制最小噪声或在协方差变得非正定时加小量对角项。
在 PostgreSQL 中的存储格式 协方差矩阵与状态向量可以序列化为 JSONB、数组或自定义复合类型。选择应基于读写性能与使用便利性。JSONB 便于灵活扩展但在大量数值计算场景下解析开销较大;数组或复合类型在函数内计算更高效。选择合理的索引与分区策略也很关键:按设备分区或按时间范围分区可以显著提高批量重算或单设备回溯查询的性能。 异常处理与观测过滤策略 GPS 数据通常包含离群点与突变。在更新步骤中可以利用设备上报的置信度(HDOP)来调整测量噪声,使低置信度观测对估计的影响减小。
在极端异常情况下,甚至可以跳过该观测的更新,仅执行预测步骤,从而避免异常观测扭曲历史估计。对于长期静止或速度为零的场景,滤波参数可自动调整以降低漂移。 批量重处理与可重复性 离线重算是一项常见操作,尤其在调参或数据修复后。为了保证可重复性,建议在设计时记录用于重算的滤波参数与随机种子(若用到随机化),并在版本控制中管理 SQL 脚本。利用自定义聚合进行批量处理时,确保聚合是确定性的并且严格按照时间戳排序。如果轨迹存在相同时间戳的样本,需设计明确的二次排序键来保证顺序一致性。
在 Neon Serverless 上的实践与好处 将 Postgres 与卡尔曼滤波工作负载部署到 Neon 等 serverless 平台有很多便利。Neon 的自动扩缩容、分支环境与无状态连接池(集成 pgBouncer)使得测试不同参数、在临时环境中进行离线重算或在不影响生产的情况下进行性能对比变得更简单。对于探索性分析或短时高峰负载,Serverless 模型可以节省成本并提供弹性资源。不过需要注意在线过滤会导致插入延迟增加,需评估是否接受该延迟或将大部分滤波工作移到离线批处理。 示例与上手指南 开源实现可以作为良好起点,traconiq 的仓库 github.com/traconiq/kalman-filter-neon 包含示例 schema、主要函数与基准脚本。建议先在开发数据库中运行示例 schema,理解 kalman_step 与 kalman_upsert_position 的签名与行为,然后在少量设备上做端到端测试。
调优测量噪声与过程噪声是关键步骤,利用带有 HDOP 的真实数据进行参数搜索能够显著提升滤波质量。 性能调优建议 对于需要高并发插入的场景,考虑将在线滤波逻辑异步化:先写入原始数据,再由后台进程或队列系统消费并更新平滑结果,这样可以保持写入路径的低延迟且不丢失平滑能力。对于离线批量处理,优先使用自定义聚合并在执行前确保表按设备与时间排序,必要时利用分区与并行查询来提高吞吐量。监控查询计划并针对热表建立合适索引,避免在聚合或窗口函数中进行不必要的顺序扫描。 实际案例与经验教训 在真实生产环境中,卡尔曼滤波可以显著改善路径平滑性并减少异常点对下游聚合的影响。但是实现过程中常见的问题包括协方差数值不稳定、边界条件处理不一致以及在高并发写入时的性能瓶颈。
合理的测试覆盖、逐步部署(先离线后在线)与监控能大幅降低风险。对于业务侧,建议与产品团队明确对"平滑"的期望(更保守 vs 更敏感),以便在滤波参数上达成权衡。 结语 在 Postgres 中实现卡尔曼滤波既是工程挑战也是提升数据质量与简化架构的机会。通过在数据库层面处理 GPS 平滑,可以提高数据可用性,减少外部管道复杂度,并在离线批处理时借助自定义聚合实现高效重算。无论选择在线即时过滤还是离线批量处理,理解滤波算法、妥善管理状态与协方差、并按需在 Neon 等平台上利用弹性资源,都是成功部署的关键。对于需要在数据库内部执行复杂时间序列估计的团队,结合开源实现与上述实践建议可以快速建立稳定且可扩展的平滑流水线。
。









