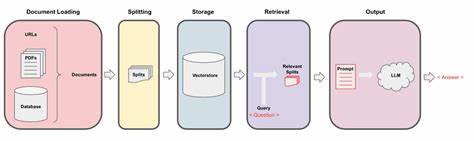
随着人工智能和自然语言处理技术的快速发展,信息检索与智能问答系统的精准性和效率成为了研究重点。WikipeQA数据集作为一项公开且专业的评测资源,在设计和验证网页浏览代理(web-browsing agents)及检索增强生成系统(Retrieval-Augmented Generation, RAG)方面,提供了坚实的实验基础和实际考验环境。本文将从数据集本身的构成、主要特点、实际应用场景及未来潜力等方面进行深入分析,帮助业界与学界全面认识和利用这一关键资源。WikipeQA数据集诞生的初衷是为了解决传统问答系统评估过程中样本缺乏、多样性不足的问题。以维基百科的真实问答对为核心内容,WikipeQA不仅涵盖典型的事实型问题,还融入了复杂长文本的回答,使问答匹配难度提升,更接近现实检索与生成挑战。数据的来源涵盖了成千上万条从维基百科精选的问题与相关段落,所有数据均为英文、采用高效的parquet格式存储,便于快速读取和批量处理。
一个显著优势是数据集规模适中,样本在1,000至10,000范围内,既保证了训练有效性,也适合各类算法的快速迭代测试。该数据集支持多种开源库调用,如Hugging Face的Datasets库、pandas等,极大方便了研究者和开发者进行数据分析、模型训练和比对。评测领域涵盖文本匹配与回答生成两大模块,符合当下智能问答技术的发展趋势。网页浏览代理需要在实时环境中通过不断爬取网页抓取相关信息,然后再进行筛选与回答生成。WikipeQA稳定且多样化的数据结构,为这类系统提供了验证智能抓取及信息整合能力的基石。检索增强生成系统则在语义检索和自然语言生成之间建立桥梁,通过有效调用知识库内的内容来提升回答的准确性和可信度。
WikipeQA提供的文本及问题对,检验了模型在检索与生成环节的协同表现,也帮助优化了端到端流程。使用WikipeQA数据集时,研究者可以重点关注几个关键指标,如准确率(accuracy)、召回率(recall)和F1值,对答案匹配效果进行全面评价。同时,可借助BLEU、ROUGE等自然语言生成评测指标,检验系统生成文本的自然程度和语义完整性。尤其是在RAG系统中,这些综合指标成为衡量系统成熟度的不可或缺工具。相比其他传统数据集,WikipeQA在问题和答案源文本长度的分布上更具挑战性,可以有效激发模型处理长文本的能力。此外,其开放源代码和MIT许可协议促进了社区广泛共享和二次开发,推动了该领域的快速技术创新。
许多顶尖研究机构和技术企业已将WikipeQA作为基准数据进行模型训练和评测,为智能问答、智能客服乃至知识图谱问答系统的设计提供重要支撑。该数据集还促进了多模态技术的引入,在文本之外,结合图像、视频等数据资源,倾向于实现更加丰富的智能交互体验。未来,WikipeQA有望与其他大型知识库及动态网络信息融合,提升模型对最新信息的响应能力,也可能引入多语言版本,扩展其全球适用性。此外,随着技术提升,围绕WikipeQA构建的端到端自动网页浏览与问答机器人,甚至能够广泛应用于医疗、法律、金融等领域的专业问答服务,从而大幅提升用户获取信息的效率与准确性。总结来看,WikipeQA不仅是一个简单的问答数据集,更是推动网页浏览代理和RAG系统评估和发展的核心资源。其实际应用价值、数据设计理念以及不断扩展的生态系统,为自然语言处理相关领域的研究与落地应用创造了巨大机遇。
技术开发者和学者应积极探索WikipeQA数据集的潜力,结合前沿的深度学习算法和增量训练技术,不断打磨更智能、更高效的问答解决方案,助力智能信息时代的到来。