随着人工智能技术的迅猛发展,围绕其底层基础设施的讨论也日益升温。在AI训练和推理的过程中,计算资源的调度与管理变得尤为关键。而Slurm和Kubernetes作为两大主流调度与编排工具,分别代表了不同的设计理念和技术生态。本文将深入探讨Slurm与Kubernetes在AI基础设施中的应用背景、优势局限以及它们如何在学术高性能计算与云原生现实之间形成鲜明对比。人工智能工作负载的复杂性和多样化,对基础设施提出了前所未有的挑战。Slurm诞生于2003年左右的科学计算领域,专注于固定集群上的长批处理任务,力求最大化每一秒CPU资源的利用率。
它的设计理念强调对资源的严格保证和批量作业的高效调度,非常适合传统的高性能计算环境。相比之下,Kubernetes诞生于2014年的Google,初衷是管理水平扩展性强、能够自动容错的无状态微服务应用。它推崇云原生架构,支持动态弹性伸缩、多租户隔离及无缝升级等现代应用所需的灵活特性。然而,人工智能工作负载既需要静态集群的稳定高效,又要具备动态调度和弹性扩展的能力,使得Slurm和Kubernetes均面临各自的不足和挑战。AI研究人员往往钟情于Slurm那种直接且确定的作业提交方式。通过简单的bash脚本如sbatch实现任务的批量提交和调度,传统的Slurm环境能够保证“团体调度”,即分布式训练所需的所有GPU资源同时被分配,避免了部分资源等待造成的性能瓶颈。
尤其在训练大型模型如数十亿参数的LLM时,这种资源分配的确定性极具价值。更重要的是,Slurm保证资源使用期间的独占性,避免了资源被意外抢占而中断长时间运行的训练作业。然而,这样的优势伴随而来的是一些亟需解决的问题。Slurm在资源隔离方面存在不足,缺乏对内存等非GPU资源使用的严格限制,导致某些作业因资源超额消耗而影响其他任务的稳定性。此外,传统Slurm集群通常是固定规模且单一地点的,难以应对突发的资源需求激增,无法实现云端弹性扩展。推理服务作为人工智能应用的重要环节,在Slurm平台上部署显得笨拙,缺少针对在线服务的设计支持,难以满足低延时、高并发的需求。
管理体验上,Slurm的界面较为简陋,主要依赖命令行工具,缺乏官方标准化的图形界面,增加了操作门槛。软件环境的一致性维护也要求集群内所有节点必须保持严格统一,增加了维护难度。相比之下,Kubernetes平台则犹如一站式的云原生解决方案,拥抱异构、多区域及多云环境。平台运行时能够纵向和横向扩展计算资源,实现按需调用,避免资源浪费。支持从训练任务到数据流水线再到在线推理的多样应用,统一管理极大降低了架构碎片化风险。丰富的生态系统提供了强大的监控、日志、调度优化工具,项目如Kubeflow构建了面向机器学习的高层次抽象,简化模型训练及部署流程。
但Kubernetes的设计并非完全贴合人工智能的工作负载特征。默认调度器缺少针对“团体调度”的原生支持,容易在分布式训练资源分配上陷入死锁。同时,Kubernetes的配置文件复杂且难以调试,对于习惯命令行的研究人员而言,学习曲线陡峭。交互式开发环境的构建亦较繁琐,阻碍了高效的模型调试与迭代。推理服务的弹性伸缩能力虽强,但在保障训练作业资源隔离和稳定性的前提下,仍需额外扩展来应对AI独有的资源需求波动。为缓解Slurm与Kubernetes各自的短板,业界推出了不少创新的混合方案。
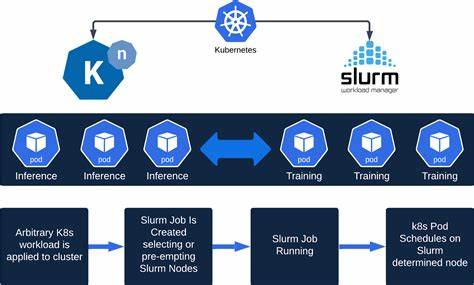
例如将完整的Slurm系统运行在Kubernetes之上,将Slurm集群作为Kubernetes的一个自定义资源进行管理。此类方案保留了Slurm的熟悉接口和调度优势,同时借助Kubernetes的云原生弹性和多云支持。但是这也带来了节点长时间被Slurm进程占用而无法充分共享的资源浪费问题,且整体配置和维护变得更加复杂。进一步的改进还包括引入诸如Volcano、YuniKorn、Kueue等高级批量调度器,这些项目针对Kubernetes进行优化,提升调度吞吐与分布式作业调度能力。虽然性能得到提升,但复杂度仍高,用户需要面对繁琐的配置和运维压力。另一种趋势是采用“训练在Slurm,推理在Kubernetes”的工作流,将训练阶段集中在高性能、稳定的Slurm集群中执行,而推理服务部署在灵活的Kubernetes环境,实现各自优势最大化。
然而,这种分离策略带来了维护多套基础设施的运营成本和资源碎片化等挑战。众多挑战催生了抽象层解决方案的兴起。以SkyPilot为代表的新型工具,通过提供统一的资源管理接口,实现跨云、跨平台的资源调度与负载均衡。用户只需编写简洁的配置文件,便可无缝切换底层执行环境,无论是Kubernetes集群还是多家云厂商的GPU资源。这种抽象极大降低了AI团队对底层基础设施的理解门槛,让研究者专注于模型与算法创新,避免陷入复杂的部署和运维陷阱。此外,SkyPilot具备自动故障切换和资源发现功能,扩大了弹性调度的边界,提升整体资源利用率。
总结来看,Slurm与Kubernetes各自代表了人工智能基础设施的两个极端,一个扎根于学术高性能计算世界,另一个深耕云原生现代软件生态。当前AI工作负载的多样性及复杂性要求两者的不断融合与演进。未来,业界应更多关注提升AI团队的使用体验和降低运营复杂性,从根本上将基础设施“隐形化”。微软、谷歌等巨头正在加码 Kubernetes的AI适配性研发,SchedMD则持续推动Slurm的云端一体化。唯有借助抽象层和智能调度机制的创新,才能真正实现资源弹性、高效协同和跨云多区域的无缝支持,助力AI技术的可持续快速发展。AI基础设施的理想藍图或将不再是二选一的调度系统,而是多种力量协同的生态体系,让研究者和工程师能够轻松驾驭海量算力,应对不断迸发的智能计算需求。
未来,人工智能领域的成功将属于那些能够用抽象化能力桥接硬件复杂性与业务需求的组织和平台,推动从学术科研到工业应用的全链路创新。