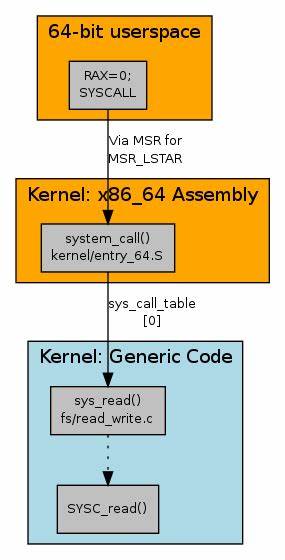
近年来,生成式人工智能技术如火如荼地发展,带来了内容创作的革命性变化,也不可避免地带来了一系列新的安全与隐私挑战。深度伪造图像、自动生成内容以及通过大量数据训练AI模型的现象日益普遍,在带来便捷的同时,个人照片、艺术作品、敏感视觉信息的安全问题日益凸显。面对这一局面,如何有效保护数字图像免受未授权AI模型操控,成为业界和学术界亟需攻克的难题。基于此诉求,来自独立研究者Rijal Saepuloh提出了一种独特的解决方案——适应性噪声算法(Noise Adaptive Algorithm),利用动态“自适应蜘蛛网”结构巧妙嵌入图像,旨在阻断AI驱动的恶意操作,同时保证人眼观看体验的无损感受。 这项创新技术的核心在于智能噪声嵌入,即通过生成一种非随机、动态多层的噪声网格结构。不同于传统水印技术或典型的数字噪声,这种自适应蛛网结构依托于图像中检测到的人物主体自动调整布局和属性,使得训练生成模型时的图像特征被扰乱,结果导致AI生成内容陷入逻辑错误或生成失败。
同时,视觉效果上保持绝对隐形,不产生任何影响画面质量的可察觉痕迹。该机制还考虑到截图及屏幕拍摄场景,噪声结构直接嵌入像素数据中,增加了图像在多种复制环境下依然具备防护能力的可能性。 值得关注的是,用户可以灵活切换“AI友好”与“受保护”两种输出模式。所谓“AI友好”即在符合授权需求的情形下关闭保护机制,允许图像在AI模型的训练或生成中自由使用;而“受保护”则激活噪声屏障,防止图像被生成模型误用,用户能够自主掌控个人数据的使用边界,强化数字版权和隐私安全。 这种技术的提出恰逢生成式AI技术快速集成于商业和个人应用场景的关键时期。例如Google的Veo等新兴技术依赖海量图像进行训练,若在普遍范围内缺乏有效防护措施,极易引发个人隐私泄露、艺术作品侵权、虚假内容泛滥等风险。
适应性噪声算法作为一套可行且人眼不可感知的防护策略,填补了传统防护手段的空白,有望在数字版权管理、内容真实性核验、反深伪技术领域发挥重要作用。 从技术架构角度来看,“Adaptive Spider Web”结构基于多层次、动态生成的网状噪声,将复杂的数学建模与图像处理算法融合,确保噪声分布因应主体内容的位置灵活调整。该结构设计不仅令AI模型难以识别和绕过,更为重要的是其嵌入的噪声对常规人眼视觉认知几乎无扰动,实现了保护与用户体验的完美平衡。该方法同时具备很高的可扩展性,既适用于单幅图像,也兼容视频流媒体的连续帧处理,为广泛的数字内容场景提供潜在的安全保障。 与此同时,这一研究理念的开源公开有助于推动全球关于负责任AI使用的共识建设。通过前沿的防御机制展示,项目旨在引发更多开发者、研究机构及政策制定者的关注和合作,促进形成覆盖广泛、兼具技术性与道德指向的数字图像保护生态体系。
特别是在深度伪造检测和内容出处核查等领域,该技术提供了一种颇具创意的补充手段,增强了整体防护的多层次效果。 此外,项目创作者Rijal Saepuloh公开征集科研合作与政策对话,体现了数字安全问题的多方共治理念。当前独立力量虽资源有限,但在理念传播、技术演示与商用推进方面表现积极,期待通过跨界协作与技术共享,推动适应性噪声技术的进一步优化和实际落地。未来或有望孕育出更智慧的图像防护工具链,助力数字内容创作者和公众用户共同构筑数字时代的安全边界。 综合来看,适应性噪声算法及其基于“自适应蜘蛛网”的防护结构,为解决数字图像面临的AI滥用风险提供了全新思路。它不仅是一种技术创新,更是一种理念创新,反映了在智能时代保障视觉数据安全的迫切需求和可行路径。
随着该技术方案的深入研究与广泛应用,数字媒体生态的诚信与安全水平有望大幅提升,推动面向未来的健康、可信和负责任的AI内容生成环境的建设。 未来,随着生成式AI技术持续演进,图像安全领域也将面临不断变化的挑战。适应性噪声算法作为一种动态且灵活的防御机制,展现出极高的适应性潜能。配合先进的检测验证手段及用户隐私控制工具,形成综合防御战略,将成为数字视觉信息安全的重要基石。通过多方共同努力,期待实现人机协同、安全共筑的数字内容新时代。在全球信息化浪潮中,每一张图像的真实性、权利与自由都应受到尊重和保护。
适应性噪声算法为这场保护战役贡献了有力武器,带来了更具创新深度的解决视角。如今,这一项目已迈入公开阶段,期待更多领域的专家学者、企业人士及政策制定者参与,共同推动视觉媒体防护技术迈向更高水平,迎接数字未来的挑战与机遇。