随着人工智能技术的迅速发展,Claude作为Anthropic旗下的先进语言模型,服务着全球数百万用户。然而,2025年8月至9月间,Claude的响应质量出现了罕见的波动,用户体验受到了明显影响。此次性能退化事件由三起关键基础设施漏洞叠加导致,本文将对这三个问题的发生背景、技术细节、排查过程以及最终解决方案进行深入解读,帮助读者全面了解大型分布式AI系统的技术挑战与应对策略。 Claude的部署环境极其复杂,它被应用于包括AWS Trainium、NVIDIA GPU和Google TPU在内的多种异构硬件平台,每个平台均需针对特定硬件特性进行深度优化。在保证模型一致性的同时,也带来了极高的维护难度。任何一处基础设施的变更,都必须经过全面且严谨的验证才能上线。
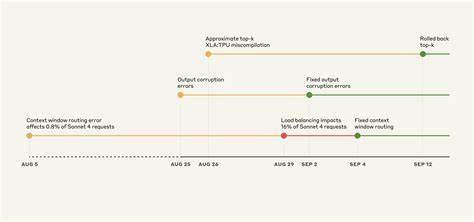
这次事件的三个问题均发生在8月中旬至9月初,时间相互重叠,极大地增加了故障诊断的复杂性。 第一起问题源自上下文窗口路由错误。Claude Sonnet 4模型的部分请求被误导向了原本为1百万Token上下文窗口设计的服务器。起初仅影响约千分之八的请求,但由于8月29日负载均衡策略调整,被错误路由的请求比例迅速提升,最高峰时达到了16%。错误的路由导致部分用户连续向错误的服务器发起会话请求,形成"粘性路由"效应,使得问题更加持久和明显。此故障的根本原因在于路由逻辑未能正确区分不同上下文规模请求,解决方案是修正路由规则并逐步完成全平台的修复部署,最终于9月中下旬全部完成。
第二起问题发生在8月25日,关联到Claude API TPU服务器上的运行时性能优化配置错误。此次配置使得在生成文本的过程中过分提升了某些本应极少出现的Token概率,导致在英文提示下出现了诸如泰文或中文等语言字符,甚至出现明显的代码语法错误。这类输出异常破坏了生成文本的连贯性和准确性,影响了部分使用特定模型版本和平台的用户。该问题仅限于Claude自身API平台,没有波及第三方平台。团队迅速锁定问题点并于9月2日回滚相关优化,同时引入了新检测机制,通过筛查异常字符输出来防止类似问题再现。 第三起问题最为技术复杂,涉及XLA:TPU编译器中的近似Top-k采样误编译漏洞。
Claude模型在生成下一个Token时,需要从概率分布中采样,其中使用了Top-p抽样技术以避免产生无意义的词汇。但为提升性能,部分模型采用了近似Top-k排序算法,该算法在特定条件下返回的结果严重错误,甚至可能丢失最高概率的Token。这一故障长期被隐藏,由此前的补丁间接掩盖,直到8月下旬更新采样代码后暴露出来。由于该错误表现出高度不确定性,且依赖调用顺序、批量大小等多种外部因素,稳定复现非常困难。团队最终决定弃用近似算法,改用精确Top-k排序,同时统一关键计算在32位浮点数精度下运行,牺牲了部分效率以保障生成质量。与XLA:TPU团队合作,针对编译器底层漏洞进行修复也同步进行中。
这三起问题的诊断过程受到了诸多挑战。首先,Claude本身在出现偶发错误时往往能够自我恢复,因此传统的自动化评测指标未能准确捕捉到质量下降的信号。其次,用户反馈虽有所增加,但相互矛盾且不易关联具体变更。再加上团队对用户隐私的严格保护措施,在调查期间无法全面访问用户与模型间的交互数据,极大限制了问题复现与定位的效率。基础设施环境复杂多变,不同硬件平台受影响程度各异,内部验证难度陡增。 为防止将来类似事件,Anthropic已采取多项改进措施。
评测体系将升级为更加敏感和细粒度的质量监控机制,能够更精准区分细微性能变化。此外,评测的覆盖范围将扩展至实际生产环境中,确保第一时间捕获真实用户体验中的异常。同时,开发团队正在建设更完善的调试与反馈处理工具,旨在在尊重用户隐私的前提下迅速响应社区反馈,加速故障检测与修复流程。 此外,Anthropic鼓励广大用户继续积极提交反馈,包括异常表现说明与具体示例,这些数据成为排查根本原因的重要线索。团队也欢迎开发者和研究人员将创新的模型评价方法分享给社区,以形成多维度的检测合力,共同推动模型质量提升。 综上所述,Claude近期的代码退化事件反映了部署大型分布式AI系统时不可避免的复杂风险,涉及软硬件协同与编译系统底层交互的深层次难题。
Anthropic在面对挑战时展现了高度的透明度和技术负责精神,详细公布问题细节及改进方案,对业界维护模型稳定性具备参考价值。随着相关修复措施落地,Claude的性能和可靠性正快速回归正轨,为未来的持续创新奠定坚实基础。用户和开发者均应关注此次事件带来的启示,提升对多平台、异构计算环境下AI产品复杂性的认识,以共同应对日益增长的人工智能应用需求。 。