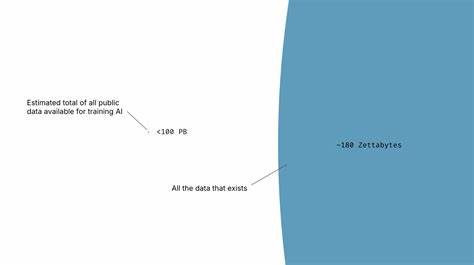
人工智能(AI)的进步离不开数据的支持,每一次技术的重大飞跃几乎都伴随着可用数据量的显著增加。然而,当前AI领域普遍存在着"数据峰值"的担忧,甚至有业内专家直言人类现有数据资源已经被耗尽。乍看之下,似乎我们正在面临数据枯竭的困境,但深入分析全球数据现状发现,事情并非如此简单。数据实际上远未枯竭,问题的根源在于数据难以被AI系统有效利用 - - 这是一个存取障碍,而非单纯的资源短缺。当前领先的AI模型训练数据规模多为数百TB,虽然听起来庞大,但与全球已经数字化的180至200泽字节数据相比,仅是一粒微尘。全球数据总量已是AI训练数据的数百万倍之多,然而这些庞大而宝贵的数据资源却未被充分利用,关键原因在于数据所有权和控制权的复杂关系。
数据所有者担心一旦共享数据,便会失去对数据的掌控权和使用权,数据流通导致的无限复制性质又使得数据价值难以保持,令市场机制难以顺畅运行。这种矛盾导致各方不愿轻易开放数据资源,从而限制了AI模型训练所需的大规模高质量数据供应。近年来,AI领域尝试通过生成合成数据和优化计算策略来缓解数据不足的问题,但这些方法仅是对现有数据的压缩或利用,并非真正解决数据增长的根本途径。对私人和企业拥有的数据来说,其独特的价值不仅体现在规模巨大,更体现在数据的准确性、结构化程度以及其对现实世界的贴近性。医疗电子病历、金融交易数据、工业传感器记录、供应链信息等数据类型为AI模型注入了高质量的训练素材,具备成为未来AI革命动力的重要潜力。要想真正释放这笔数据"金矿",必须解决数据共享中存在的激励错配。
数据所有者若无法保持对数据的使用控制并获得持续收益,即使他们拥有海量数据,也不会主动进行共享。基于此,专家提出了一种被称为归因控制机制(Attribution-Based Control,简称ABC)的新框架,旨在实现数据共享的同时确保数据所有权和控制权不被侵犯。ABC并非单一技术,而是一整套设计准则,要求AI系统支持具体数据源对训练成果的贡献明确可识别,并允许数据所有者控制其数据的应用场景。通过这样的设计,数据从一次性赠与转变成持续收益的资产,犹如音乐人在歌曲播放时获得版税,从而极大激发数据所有者的共享积极性。技术方面,ABC依托于模型分区技术和隐私保护基础设施来实现。模型分区技术能让AI系统明确区分不同数据源对模型的贡献,例如混合专家模型(Mixture of Experts)和检索增强生成模型(Retrieval-Augmented Generation)等架构,有效保持数据源的独立性。
不仅如此,隐私保护技术如同态加密、联邦学习、硬件安全执行环境、零知识证明及差分隐私等,构建了完整的保密体系,确保数据所有者的原始数据不会被泄露,同时实现安全的协同训练和推断。这些技术结合使得ABC不仅是理论可能,更是当前即可部署的现实方案。在政策层面,专家建议美国政府借鉴ARPA网络(ARPANET)的成功经验,针对ABC技术发起一项全新的政府引导计划。通过DARPA设立专门项目团队,整合和推动ABC相关核心技术的发展,国家科学基金会(NSF)支持早期应用者进行系统落地,国家标准与技术研究院(NIST)制定ABC国际标准,形成政策、技术、市场的合力推手。这样的战略布局不仅有望打破目前AI训练数据的获取瓶颈,也将极大提升美国在全球AI技术竞争中的领导力和创新力。深刻理解这场数据存取革命对AI的意义,意味着我们正在迎来从碎片化、封闭数据生态迈向开放、互联智能系统的关键转折。
借助ABC模式,未来数据所有者与AI企业能够构建共赢的数字经济,数据价值与AI创新互为推动,推动医疗、金融、制造等关键领域取得突破,提升社会整体福祉。当前,面对日益严苛的隐私法规和日益复杂的数据所有权环境,如何有效利用全球海量数据资源成为推动人工智能发展的重中之重。ABC为我们提供了一条可行的道路,通过技术创新与政策驱动同步发力,解锁那被封存当前AI体系之外的亿万倍数据资源。只要坚定实施ABC战略,未来的AI不仅会更强大,也将更加尊重数据所有者权益,成为促进科技进步和社会繁荣的纽带。 。