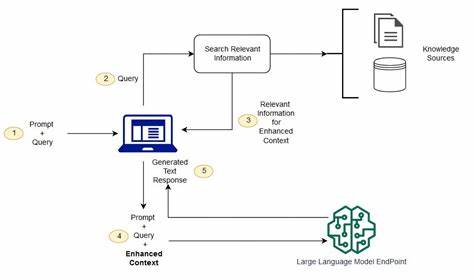
在当今快速发展的数字时代,人工智能正以前所未有的速度影响着人们的生活。特别是在语音合成和深度伪造(Deepfake)技术领域,这种影响变得尤为显著。深度伪造技术利用深度学习算法,可以合成人类几乎无法区分的真人声音,这导致语音诈骗手段更加真实和危险。传统通过声音识别身份的安全方法已经受到严重威胁,给金融、医疗、客服等行业带来了巨大的安全隐患。深度伪造电话的出现使得诈骗者能够冒充亲友、公司高管甚至银行职员,以假乱真地骗取钱财或敏感信息。据Truecaller的一份报告显示,利用克隆声音进行的冒充诈骗造成的损失每年高达250亿美元,这一数字在未来只会持续攀升。
科技门槛的降低使得这些合成声音的制作成本越来越低,哪怕只有几秒钟的语音录音,也能生成一个逼真的虚假电话。与此同时,社会老龄化、数字认知差异等因素让部分群体对这类深度伪造电话更加容易上当受骗。在此背景下,传统单纯依靠人工经验辨别电话真假显得力不从心。如何利用先进技术手段构建高效、准确的深度伪造电话检测系统,成为当前业界亟待解决的难题。以频谱图AI为核心的音频检测技术日益被证实具有强大的潜力和应用价值。频谱图是将声音频率随时间变化的视觉表现,能够捕捉到语音信号中微妙而复杂的特征。
通过机器学习模型分析频谱图,可以识别出深度伪造音频中难以察觉的伪造痕迹。要构建可靠的检测系统,首先需要准确代表真实和伪造音频的高质量数据集。ASV Spoof 2019数据集是该领域的权威数据资源,涵盖了多种攻击方式,包括文本转语音(TTS)、语音转换(VC)和重放攻击等,该数据集经长期研究验证,适合用作反欺诈模型的训练数据。此外,为了提升模型的泛化能力,需要对数据进行增强处理。时间偏移、音量调整、噪声添加和音高变化等数据增强技术,使模型能够适应更多样化的语音输入,有效提升识别准确率。这些增强方法帮助模型在面对不同环境和设备采集的音频时,依然能保持稳定表现。
基于频谱图的特征提取被广泛认可为语音识别的重要手段,其中梅尔频谱图(Mel Spectrogram)因其对人类听觉的贴近而备受青睐。通过转换原始音频为梅尔频谱图,模型能够更清晰地捕获音频中的频率模式与时序信息,进一步识别语音的真实性。为了防止模型过拟合,频谱图掩蔽(masking)技术也被引入,通过随机遮挡频率和时间区域,增强模型的鲁棒性,应对现实中的部分音频损坏或信号丢失问题。整个检测流程中,将原始音频处理为经过多种增强的梅尔频谱图,输入深度神经网络模型,如ResNet结合双向门控循环单元(Bi-GRU)进行训练,从而实现对深度伪造语音的分类。实验证明,这种方法可以在较少训练周期内,达到95%到97%的精确率和召回率,表现优于传统方法。同时,利用现代可视化工具如Streamlit构建用户界面,实现对上传音频的实时判别,使得非技术用户也能方便快捷地识别真假语音。
除了技术实现,专业人士强调了行业数据的多样性和平衡性的重要性。仅依赖某一类伪造样本会导致模型偏差,难以面对日益丰富的合成技术。通过结合真实的物理环境数据和合成数据,模型得以具备更强的识别能力。反对欺诈专家也指出,随着深度伪造生成技术趋于成熟,只有持续更新和训练的检测模型才能追上诈骗者的步伐。面对金融、电信和医疗等行业频频遭遇的语音诈骗,企业应及时部署基于频谱图AI的检测系统,加强员工和客户防范意识,定期更新数据和算法,构建前瞻性的安全防线。语音作为曾经极其可信的身份凭证,在深度伪造技术面前已不再万能。
通过引入频谱图AI检测技术,不仅可以及时识别潜在的诈骗电话,还能帮助企业和用户重建信任环境,保障数字通信的安全稳定。未来,随着AI技术的不断发展及其在反欺诈领域的深度融合,将涌现更加智能和高效的防范工具,为应对深度伪造带来的安全挑战注入更多信心和力量。语音骗局日益智能化,频谱图AI检测技术正成为守护数字世界诚信的重要利器。具备多样化的训练数据、完善的音频增强策略以及先进的神经网络模型协同工作,是面对深度伪造威胁的核心组成部分。只有持续加强技术研发和行业合作,才能真正遏制越来越真实的伪造电话,为每个使用者筑起坚实的安全盾牌。