随着人工智能技术的迅速发展,语音助手已成为智能手机、智能家居和便携设备中不可或缺的功能。然而,语音助手背后的自然语言处理(NLP)模型,尤其是基于变压器结构的大型神经网络,如BERT、GPT和T5,计算需求庞大,给计算资源和响应速度带来了严重挑战。硬件加速器的研发因此成为提升语音助手性能及用户体验的关键路径。传统硬件加速器往往针对特定模型,缺乏对多样化应用的有效支持,且在处理变动不定的输入规模时效率较低。为此,一种基于可变阵列结构的可扩展变压器加速器架构应运而生,专为适配语音助手的多模型需求和变长输入进行了优化。核心技术之一是采用可变形阵列设计,结合行优先数据输入方式,实现对矩阵运算中词数变化的灵活适配。
这样不仅减少了时钟周期和延迟,还有效降低了内存访问停顿,提升整体加速效率。不同于传统的固定大小方阵结构,该架构的可变阵列能够根据实际输入调整阵列规模,避免硬件资源浪费,体现了极高的硬件利用率。该系统中的多处理元素(PE)通过并行输入数据与权重的混合流水线结构,完成大型矩阵乘法运算,显著提高计算速度,同时确保对多头注意力机制中的查询(Q)、键(K)、值(V)矩阵操作的兼容性。通过利用有限状态机(FSM)实现计算控制和早停策略,进一步减少空闲计算周期和优化执行效率。另一项关键创新是基于专门设计的Radix-2软最大值(Softmax)单元,该模块使用移位和加法迭代操作替代传统的查表法计算指数函数,极大降低软硬件资源消耗。其分三阶段流水实现确保结果精度与计算稳定性,同时提升功耗效率,使整体模块更适合嵌入式应用。
此外,针对变压器模型中计算资源密集型的矩阵运算,采用了自定义16位浮点量化策略,有效在保持精度的前提下降低计算带宽和存储需求。该浮点格式优化了指数和尾数的分配,有效避免了溢出和精度损失,从而提升了计算速度和功耗表现。量化方法省略了传统处理中常见的层归一化步骤,不仅加快了运行速度,还简化了硬件设计,确保在多模型场景下的适配和良好性能。软件层面,系统预置了高效的数据预处理算法,包括零填充和分块矩阵乘法累计策略,以保证不同规模输入均可顺利计算。零填充策略弥补了矩阵大小与阵列规格不匹配的情况,防止运算瓶颈产生,而分块计算则让超出硬件处理能力的超大矩阵分段处理,保证整体计算高效有序。该硬件+软件协同设计方案在使用Xilinx FPGA及ARM Cortex-R5嵌入式处理器平台上得到了验证。
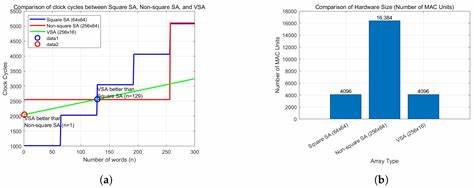
实验显示,相较于传统固定阵列加速器,新的可变阵列方案在诸如多头注意力和前馈网络架构组件的核心计算过程中,时钟周期显著降低,运行速度提升近三倍,且准确率稳定在97.6%以上。尤其是对词数动态变化的支持凸显了该加速器卓越的适应能力和场景扩展性。该架构的紧凑设计为移动端设备带来低功率耗特性,满足长时间语音交互和处理速度的需求,也有望升级至云端多模型计算任务,广泛促进智能语音识别、文本摘要、语音生成及图像搜索等应用优化。未来,该可扩展变压器加速器还具有进一步支持生成式人工智能模型及编码解码器结构的潜能,通过软件层面的灵活调整,无需更换硬件即能满足新兴复杂模型的加速需求。总的来说,基于可变阵列设计的变压器加速器代表了AI芯片方向上的重要进展,强有力推动了语音助手的多样化应用与计算效率变革,从而提升用户实时交互体验和智能应用的广泛普及。随着人工智能生态的日益丰富,提升软硬件协同设计效能将成为智能设备性能竞争的关键,而该技术的推广应用将为移动智能时代带来更高响应速度、更低功耗及更强大功能支持的语音交互新高度。
。