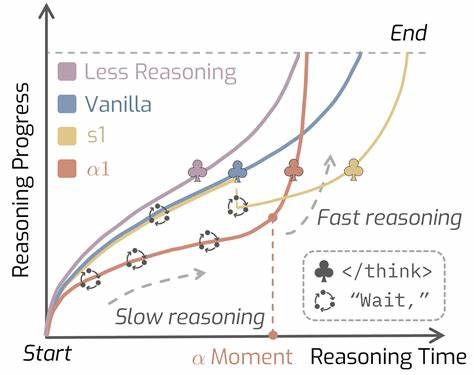
随着人工智能技术的不断进步,推理模型在解决复杂问题时的表现成为业界关注的核心。AlphaOne作为一种创新的推理框架,提出了通过调节推理模型在测试阶段的思维速度,实现智慧与效率兼顾的解决方案。该框架由来自伊利诺伊大学香槟分校和加州大学伯克利分校的研究团队联合研发,面向大规模推理模型(Large Reasoning Models,LRMs),从理论和实践层面为智能推理领域带来了显著的突破。 推理过程中的“快思考”与“慢思考”决策问题一直困扰着AI模型开发者。慢思考如同人类在面对复杂问题时的深度分析,需要较长时间的推理活动;而快思考则相当于经验驱动的直觉反应,更注重效率。AlphaOne框架通过引入一种称为“moment”的关键参数,以统一和扩展现有的单调缩放方法,实现了慢思考与快思考之间的灵活调节。
在moment之前的“前moment”阶段,模型采用了一种动态调度机制,通过将推理转换标记的插入视作伯努利随机过程,从而智能化地安排慢思考的频率和密度,确保模型获得充分的分析时间。而一旦跨过moment,模型则转入快思考模式,借助终止符号来快速收敛答案生成,极大提高了推理速度。 该机制的创新之处不仅在于实现了推理速度的自适应调节,还在于这一过程为提高推理准确率和计算效率提供了双重保障。研究团队通过对三个不同规模的LRMs进行综合测试,包括1.5亿、7亿和32亿参数的模型,覆盖数学问题、代码生成和科学竞赛问题等多个领域的六大基准测试,验证了AlphaOne的优异性能表现。 实验数据显示,采用AlphaOne框架的模型不仅在多个数据集上表现出了更高的准确率,还保持了较低的计算资源消耗。尤其值得注意的是,模型在慢思考阶段首先展开深入分析,保证思考的深度与严谨,而随后切换至快思考阶段,显著缩短了整体推理时间。
这种“两阶段思维模式”的设计符合人类认知过程中的决策机制,为AI推理引入了一种更加自然且高效的思考节奏。 AlphaOne还通过可视化不同思考调度策略,进一步展现了慢思考转换的高频率策略对于提升模型性能的积极作用。动态且密集的思考转变安排,能够帮助模型更灵活地适应问题的复杂程度,避免了单一思考节奏导致的推理效率瓶颈。同时,该框架使用户可以通过调整moment参数,轻松控制模型的慢思考时长,满足不同场景下对效率与准确率的差异化需求。 从应用角度来看,AlphaOne在数学竞赛题库(如AIME24、AMC23及MATH500)、代码生成挑战和科学奥林匹克题目中表现出色,展现了强大的跨领域适应能力。模型不仅能处理逻辑严密的数学推演,还能生成高质量的代码以及解决复杂科学问题,这为人工智能在教育、科研及软件开发等行业的深度应用奠定了坚实基础。
不仅如此,研究中也揭示了AlphaOne框架在实际应用中的成功案例以及存在的局限性。成功示例体现了模型在高难度推理任务中的准确与效率兼顾,而失败案例则为未来优化模型思考转变策略提供了方向,推动全体研究者不断深化对智能推理动态调度机制的理解。 AlphaOne的推出预示着智能推理模型正向更加人性化和高效化的方向迈进。它通过科学地模拟人类思维的快慢切换,开创了一条提升大规模推理模型性能的新路径。未来,随着硬件计算能力的提升和算法优化的深入,类似AlphaOne这样的快慢思考调节方法有望成为人工智能领域的主流技术,推动AI在更多复杂应用场景中发挥更大价值。 综上所述,AlphaOne不仅在技术层面提供了前所未有的推理思维调节方案,更在实践中展现了其广泛的适用性和强大的性能提升潜力。
对广大研究者和开发者而言,理解和掌握这一框架的设计理念和实施方法,将极大拓展智能推理模型的应用边界,同时带动整个AI行业迈向更加精准、高效的智能时代。随着进一步的研究与应用推广,相信AlphaOne将在未来人工智能的发展中扮演重要角色,成为推动机器智能进步的关键力量。