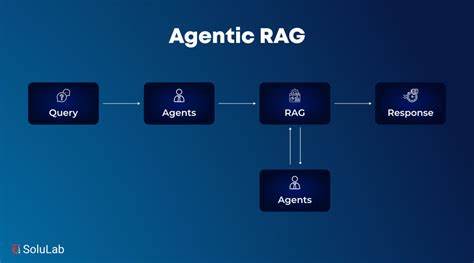
近年来"检索增强生成(RAG)"作为将外部知识喂入大型模型的主要模式广泛流行,但把知识仅仅当作上下文填充,会掩盖更深层次的设计机会。将知识视为运行时可调用的工具,而非一次性投入模型上下文,能够显著提升代理在鲁棒性、可维护性、适配性与可治理性上的能力。本文围绕为什么需要超越RAG、可行的架构模式、关键工程实践与评估指标展开讨论,帮助产品和工程团队把知识系统从"静态存储"进化为"实时记忆与指导"的核心能力。 首先需要澄清一个常见误解:RAG并非坏方法,它在许多任务上都表现优异,尤其是在需要把开放文本知识快速注入模型的场景。然而,传统RAG通常是一条单向的数据流:在向量数据库检索若干片段后将其串联进提示,交给模型生成答案。这种模式存在天然限制。
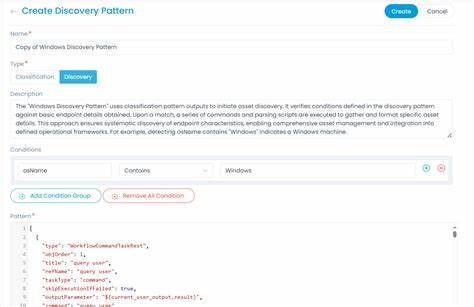
其一,检索片段常常是稠密的文本片段,对结构化信息、表模式、API约定等支持不友好。其二,单次检索与一次性生成难以支持复杂的多步推理或交互式查询,导致深度研究或复杂工作流受限。其三,知识更新与治理在这种流水线中往往难以自动化:当模型连续爆出错误或陈旧答案时,没有自然的机制把反馈转回知识库并安全地演化内容。 把知识当作第一类运行时工具,首先体现在动态指令的理念上。动态指令不是把所有业务规则塞进系统提示,而是把规则、模式、样例和领域约定保存在知识库中,按需检索并注入到代理的上下文中。以Text2SQL为例,表的schema、常见查询模版、列的业务含义以及权限约束都不应硬编码进核心模型的系统提示,而应作为可检索的、带版本和元数据的外部知识片段。
在运行时,代理根据当前用户意图检索最相关的schema与示例,并在生成过程中引用这些动态指令,从而达到更精准和更可解释的转换效果。这样的模式让系统提示更像一块RAM,用于存放核心逻辑和运行时状态;知识库则像磁盘,存放路径特定的信息片段,随取随用并支持独立更新与治理。 自适应学习是让代理系统真正"活起来"的另一个关键方向。相比静态RAG管道,理想的代理应能监控自身的对话与任务结果,识别成功或失败的模式,并把有效信息或错误案例反馈回知识库。实现这类闭环需要解决分类、信任与治理问题。首先需要可靠的自动化信号来判定哪些交互值得入库:可以通过用户显式评分、任务成功率、审计样例或A/B测试结果来筛选。
其次要设计多层次的信任机制:自动采纳低风险的改进、高置信度的分类更新;对涉及合规或安全的条目,则通过人工审核后再进入生产库。治理体系还要包含版本控制、回滚策略与可追溯的变更日志,确保任何自动化更新都可审计、可回滚并满足合规要求。 在检索策略上,单一的向量相似度不足以覆盖所有需求。混合检索(语义+关键词)在工程实践中常被采用以兼顾鲁棒性与精确度。语义检索擅长模糊匹配与同义表达,而关键词检索在处理专有名词、代码片段、表名与法律条款时更可靠。此外,对检索到的候选进行再排序(reranking)能显著提高下游生成质量。
再排序器可以是更强的Transformer模型,也可以是基于业务规则或元数据的启发式打分。为支持多跳推理,还需要构建一个允许迭代检索与合成的scratchpad或工作内存,让代理能够在多个检索步骤间累积线索、维护中间状态并逐步逼近答案。这样的设计使"深度研究"与复杂决策成为可能,而不是被压缩到一次性检索的局限里。 结构化知识与知识图谱在许多企业级场景中有不可替代的价值。向量数据库适合处理自然语言文本与语义模糊检索,但关系型数据、时间序列、实体关系和约束逻辑更适合放在关系型数据库或图数据库中。一个健壮的知识架构通常是多层次的:向量层负责语义检索,关系层负责实体与关系约束,文档层负责长文本与政策条款。
代理在运行时应能根据任务类型选择合适的知识路径,例如在回答合规问题时优先查询法规图谱,在生成报告时混合使用结构化数据与背景文档。这样的混合架构带来了更高的准确性与可解释性。 工程实现层面有若干实用技巧值得注意。知识切片的粒度非常关键:太大会降低检索精度与上下文利用效率,太小则增加检索成本并破坏语义完整性。通常对文档按语义段落或逻辑模块进行切片,并保留丰富的元数据(来源、时间戳、作者、相关领域、信任等级),以便在检索与再排序阶段综合权衡。缓存策略与异步检索能显著降低延迟;在低延迟要求的交互中,可以先用轻量检索返回关键片段,再在后台补检索更详尽信息并在需要时逐步补全答案。
安全与访问控制同样必不可少,知识库应支持细粒度权限、审计日志与加密,以防敏感信息泄露或误用。 评估与监控需要同时关注检索质量与下游任务效果。传统检索指标如Precision@k、Recall@k、MRR等仍然有用,但仅靠这些无法评估代理在真实任务中的表现。需要引入下游指标,例如任务成功率、对话满意度、人工校正率与业务关键指标(如工单解决时间、法律审查通过率)。对自适应更新的知识库还应监控变更导致的回归风险,定期进行离线回归测试与小范围A/B实验以验证更新效果。可视化工具用于追踪知识来源、检索链路与生成证据尤为重要,它不仅帮助调试,还增强了系统的可解释性与合规性。
在工具与生态方面,许多开源与商业组件可加速实现上述模式。向量存储如Milvus、Weaviate、Chroma和商业服务如Pinecone、Zilliz都提供高性能检索。检索编排与提示管理可以利用LangChain、LlamaIndex、Haystack等框架来实现动态检索、链式调用与多步推理。知识图谱与关系数据库仍然是处理实体关系的首选,GraphQL或SPARQL可用于结构化查询。再排序与可信度估计常依赖于额外的Transformer模型或二次分类器。重要的是将这些组件以微服务或可编排的流程形式组合,使知识检索、策略决策、生成与审计成为可观测的运行单元。
落地时常见的阻碍包括数据质量不足、标签稀缺、治理成本高与组织内阻力。解决之道是先从高价值、小范围的用例开始试验,例如内部知识库的FAQ自动化或特定产品域的Text2SQL服务,建立评估基线并逐步引入自动化更新与人类审查回路。另一条实践路径是把知识管理与数据工程团队紧密结合,建立清晰的知识采集、清洗、标注与上线流程,把知识看作产品而非一次性数据导入。 未来的发展方向会朝向更深层次的记忆分层与情境化能力。代理将可能拥有短期工作记忆、中期交互记忆与长期经验库,三者协同支持即时响应、会话连续性与跨会话学习。知识的可执行化也值得期待:不仅仅是被检索的文本,而是可调用的API、可运行的策略片段与可验证的逻辑单元,这将把知识变成真正的运行时工具,支持自动化决策和复合任务执行。
合规与可解释性将成为关键约束,要求每一笔自动更新都留有可审计证据并支持人工干预。 总之,RAG是构建知识驱动代理的重要组成部分,但不应被视为终极答案。把知识视为运行时的一等工具,组合动态指令、自适应学习、混合检索、结构化图谱与多步推理,可以构建更强健、可控且持续进化的代理系统。工程实践中要重视粒度设计、元数据治理、权限控制与评估体系,借助现有开源与商用组件快速迭代。把知识从静态存储变成可操作的、受控的记忆,是代理走向产业化与规模化的核心路径。 。