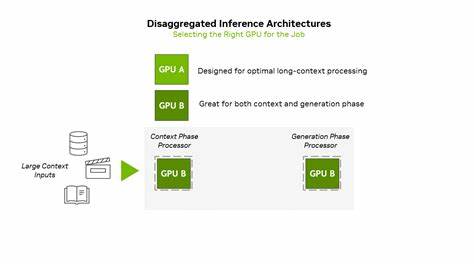
近年来,人工智能技术,尤其是大规模语言模型(LLM)的应用场景日益丰富,推动了AI推理在性能和效率上的不断挑战。随着模型从简单的自动补全工具逐步演变为具备多步推理、持续记忆和长距离上下文处理能力的智能代理系统,传统的计算基础设施已难以满足这些复杂需求。在软件开发、视频生成和深度研究等领域,AI系统必须能够处理上百万令牌的上下文信息,这对于算力、内存和网络带宽均提出了前所未有的挑战。面对这些挑战,NVIDIA推出了Rubin CPX GPU,作为全新设计的专用推理加速器,旨在优化长上下文推理工作负载的性能和ROI,同时支持先进的分布式推理基础架构。NVIDIA Rubin CPX的创新不仅在于硬件能力的提升,更在于其深度契合推理流程中不同阶段的需求,彻底革新了AI推理的架构设计。推理过程主要包括上下文处理阶段和生成输出阶段,这两个阶段对计算资源的需求截然不同。
上下文阶段高度依赖计算吞吐量,用以快速处理大量输入数据,为生成第一条输出做好准备;生成阶段则更依赖内存带宽与高速互联,实现流畅的逐令牌输出。Rubin CPX通过分离这两个阶段的处理,采用专门优化的GPU为上下文阶段提供强大算力,极大提升推理效率与响应速度。同时,通过与NVIDIA Vera CPU和Rubin GPU协同工作,为生成阶段提供持续的高速数据传输与计算支持,实现全流程性能的最大化。Rubin CPX基于NVIDIA最新的Rubin架构,具备高达30 petaFLOPs的NVFP4低精度计算能力以及128GB的GDDR7高速内存,在加速计算密集型的长上下文处理时表现卓越。其硬件还集成支持高清视频的编解码功能,以及提升3倍的注意力机制加速能力,显著优于此前GB300 NVL72系列产品。针对高价值推理应用,如大型软件项目迭代过程中的代码分析及跨文件依赖理解,Rubin CPX不仅提升了处理速度,也通过优化的资源利用帮助开发者节省宝贵时间和成本。
基于此,NVIDIA打造了包含144块Rubin CPX GPU、144块Rubin GPU和36颗Vera CPU的Vera Rubin NVL144 CPX机架,提供高达8 exaFLOPs的NVFP4算力,以及100TB的高速内存与1.7PB/s的内存带宽。该组合采用Quantum-X800 InfiniBand和Spectrum-X以太网高性能互联,搭配ConnectX-9 SuperNIC智能网络卡与Dynamo动态编排平台,实现了对百万令牌上下文推理任务的极致支持,推动AI推理规模与效率达到前所未有的水平。这种面向未来的分布式推理架构,基于全栈的SMART理念,实现了规模、性能、架构与生态系统的多维度优化。通过对上下文和生成两阶段的计算资源分离,并针对各自特点定制加速方案,Rubin CPX有效降低了延迟、提升了吞吐,同时优化了成本效益比。其支持的NVIDIA Dynamo平台能够高效协调KV缓存传输、内存管理和动态路由,保障了推理过程的流畅与稳定,为MLPerf等权威基准测试带来了刷新记录等级的表现。从经济角度看,该平台预计可带来30至50倍的投资回报率,将100亿美元的资本支出转化为高达50亿美元的营收潜力,大幅提升企业在生成式AI领域的竞争优势。
随着生成式AI在内容创作、自动化编程、虚拟现实等多领域的应用加速,Rubin CPX所代表的下一代基础设施方案,为开发者和企业提供了坚实的技术保障。不仅能够满足超大规模长上下文推理的苛刻需求,还能灵活适应未来不断演变的AI模型和应用形态,释放前所未有的创新潜能。NVIDIA Rubin CPX的推出,不仅树立了AI推理领域的新标杆,更进一步夯实了NVIDIA在GPU加速计算及智慧推理技术上的领先地位。其深度融合硬件创新与智能编排平台,结合超高带宽内存与先进网络技术,极大提升了AI推理的性能和效率,满足了当今以及未来生成式AI的严苛需求。展望未来,随着AI模型的复杂性与规模不断攀升,NVIDIA Rubin CPX将持续推动推理技术创新,助力全球AI开发者构建更智能、高效和响应迅速的应用生态。通过打造面向多样化应用场景的灵活、经济、高性能推理系统,NVIDIA Rubin CPX无疑将引领新一轮AI技术革命,为数字经济时代注入强劲动力,打造智能计算的未来图景。
。