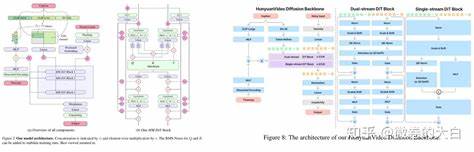
随着深度学习技术的不断进步,扩散模型在视频生成领域取得了显著突破。然而,长视频的生成仍然面临着巨大挑战,特别是在处理庞大时空信息时,高昂的计算成本成为限制模型性能提升的关键瓶颈。传统自注意力机制由于计算复杂度呈平方级增长,使得在长序列视频处理中变得极其低效且资源消耗巨大。针对这一问题,麻省理工学院Han实验室的研究团队提出了一种创新性的稀疏注意力机制——Radial Attention,旨在从根本上改善长视频生成过程中的计算效率,并实现2至4倍的训练和推理加速。 Radial Attention的设计理念源于物理学中的能量衰减原理,在实际应用中即观察到视频扩散模型的注意力分数在空间和时间距离增大时呈指数衰减趋势。换言之,视频中彼此相距较远的Token之间其注意力权重趋向于较低的数值,这反映了现实世界信号传播与能量传递的本质规律。
基于这一发现,Radial Attention设计了一套静态的预定义注意力掩码,使每个Token主要与空间邻近且时间接近的Token进行交互,而跨时序较远的交互则通过递减计算密度得以有效利用有限计算资源,实现计算效率与表达能力的平衡。 从具体实现来看,Radial Attention沿时间维度引入了指数级的计算密度衰减规则,即两个视频帧之间的注意力计算密度按照它们时间距离的对数底2进行分段递减,形成一系列对角带状结构,这些结构的宽度随时间间隔成倍变化,确保整体计算量保持在可控范围内。同时在空间维度内,机制保持同一时间帧内邻近位置的高关注度,其对角宽度随着时间距离的增加而缓慢收缩,进一步体现能量集中在空间邻域的特性。 为了适配现代硬件的高效并行计算,Radial Attention采用了块级稀疏计算,使用128×128的块作为最小计算单元,避免了细粒度稀疏带来的计算碎片化和调度开销问题。这种设计既保证了硬件友好的执行效率,也减小了内存访问延迟,提高了整体系统吞吐量。 面对长视频生成过程中模型扩展和微调难题,Radial Attention结合了低秩适配技术(LoRA),仅对查询、键、值及输出投影进行小规模微调,有效降低了训练和存储成本。
这种配合不仅使得预训练模型权重高度复用,还优化了注意力分布,提升了长视频生成的质量和效率。 从性能表现来看,Radial Attention相较于传统密集注意力方法,在生成720p分辨率、500帧长的视频时显著减少了计算负担,计算量减少达九倍,训练和推理速度分别提升3.7倍以上,同时微调过程的计算资源节省达4.6倍。这些成就使其成为超长视频生成任务中最具竞争力的解决方案之一。 视频质量方面,Radial Attention在保持与密集注意力模型相当的视觉效果的同时,实现了大幅度的速度提升。更值得关注的是,当生成的视频长度扩展至原模型的四倍以上,Radial Attention依然能够稳定地降低训练调优成本,并且在推理端实现近四倍的加速,表现出卓越的扩展性和适应性。 此外,Radial Attention兼容现有的LoRA权重,允许将其与风格迁移等其他LoRA技术结合,进一步丰富视频生成的多样性和艺术表现力,且不牺牲生成速度或者质量。
这种兼容性大幅简化了多功能视频生成模型的开发与部署。 总结而言,Radial Attention通过对时空注意力分布的物理启发和稀疏计算策略,成功将长视频生成中自注意力的计算复杂度从O(n^2)降低到O(nlogn),实现了长视频领域前所未有的效率突破。其创新的时空密度衰减设计、块稀疏实现和低秩微调方案相辅相成,形成一套完整且高效的长视频生成解决方案。随着视频内容需求的不断增长和多样化,Radial Attention所展现出的强大性能和良好兼容性,将极大推动基于扩散模型的视频生成技术走向更广泛的应用场景和商业落地。未来,研究者可基于Radial Attention探索更多时空动态建模方法,同时结合多模态学习和大规模预训练,进一步提升视频生成的质量和交互体验,开拓智能视觉内容创作的新篇章。