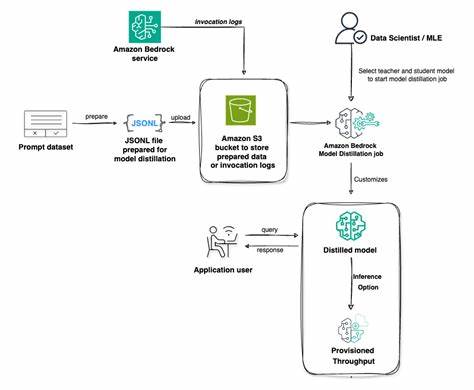
随着人工智能技术的快速发展,生成式AI在自然语言处理、智能问答、自动化办公等领域表现出巨大的潜力。然而,先进的生成模型通常伴随着巨大的计算资源消耗和高昂的使用成本,限制了其在实际生产环境中的广泛应用。为应对这一挑战,Amazon Web Services(AWS)推出了Amazon Bedrock模型蒸馏(Model Distillation)技术,通过实现高效模型压缩与优化,帮助企业在保证模型准确性的前提下大幅提升模型运行速度和降低成本。 Amazon Bedrock模型蒸馏的核心理念是利用“教师模型”指导“学生模型”,使较小、计算效率更高的学生模型能够在特定用例上达到与大型教师模型相似的准确度。具体流程中,用户首先选择一个性能卓越的教师模型,定义其所需达到的准确性目标,同时选定一个结构更小、推理速度更快的学生模型。借助用户提供的业务相关提示(prompts),系统自动从教师模型生成高质量回答,并利用这些回答对学生模型进行微调训练。
此种方式不仅大幅提升了学生模型的表现,也极大缩短了模型调优周期。 模型蒸馏技术的优势显著,首先是在性能与成本之间实现了良好的平衡。根据Amazon Bedrock的官方数据,通过蒸馏后的学生模型,其推理速度可提升至原始模型的五倍,相关成本降低高达75%,同时准确率损失不超过2%。这一特点为企业在大规模应用AI技术时节省了大量计算资源与运营成本,推动生成式AI技术向更加广泛和实用的方向发展。 除了成本控制的直接优势,Amazon Bedrock还结合了先进的数据合成技术,助力模型蒸馏过程中的数据增强。用户提供的有限提示数据会经过扩展处理,生成更多结构相似的训练样本,或通过合成高质量的示范回答进一步丰富训练集。
这种数据合成不仅提升了学生模型的泛化能力,也降低了人力标注成本,极大提升了生成模型的定制化效果和训练效率。 用户还可以灵活上传自己的生产数据,实现以真实业务数据为基础的模型调优。相较于传统的Fine-tuning需要完整的提示-回答对输入,Amazon Bedrock的模型蒸馏允许使用调用日志中的提示和响应数据,且支持基于元数据的日志筛选,避免不必要的重复生成,有效减轻了训练负担且降低整体花费。这对于企业实时迭代和个性化模型优化具有重要意义,使得人工智能应用更加贴合实际业务需求。 在功能预测方面,模型蒸馏技术也展现出重要价值。现代智能代理系统依赖函数调用能力与外部工具、API实现深度集成,准确的函数调用预测成为提升系统智能交互体验的关键。
大型模型固然表现优秀,但计算资源消耗巨大。通过模型蒸馏,较小的学生模型也能获得类似的函数调用准确率,显著提升响应速度,降低运行延迟,助力企业构建更为高效智能的自治代理系统。 Amazon Bedrock模型蒸馏支持丰富的模型生态体系,涵盖了多家模型供应商的顶级产品。例如,Amazon自研的Nova Premier (teacher)和Nova Pro (student)模型,以及Anthropic的Claude 3.5 Sonnet v2 (teacher),还有Meta发布的Llama 3.3 70B (teacher)和Llama 3.2 1B/3B (student)。多样化的模型选择支持用户根据需求灵活组合,最大化地发挥模型优势。 从部署与使用的角度看,Amazon Bedrock提供了简洁的控制台界面和丰富的API支持,用户能够便捷地开始模型蒸馏流程,无需深厚的AI开发经验即可实现定制化模型微调。
此外,AWS官方还提供详尽的用户指南、代码示例及技术博客,帮助用户快速上手并掌握优化技巧,极大地降低了企业引入先进AI技术的门槛。 展望未来,随着生成式AI需求的持续旺盛以及智能代理应用的快速普及,Amazon Bedrock模型蒸馏技术将成为企业提升AI平台竞争力和运营效率的重要利器。通过不断完善数据合成策略和优化蒸馏算法,模型蒸馏有望进一步缩小小模型与大模型之间的性能差距,推动AI技术从实验室走向更广泛的商业落地。 综上所述,Amazon Bedrock模型蒸馏融合了前沿的模型压缩技术和智能数据增强方法,为企业提供了一个高效、经济且灵活的生成式AI解决方案。它不仅降低了模型应用门槛和成本,还能够在保持高准确率的同时加速推理速度,充分满足实际业务的多样化需求。无论是面向知识检索、自然语言生成,还是智能代理中的复杂函数调用预测,模型蒸馏技术都是助力下一代人工智能发展的关键引擎。
随着更多行业开始探索智能化转型,Amazon Bedrock模型蒸馏无疑将成为数字化创新的核心支柱之一。