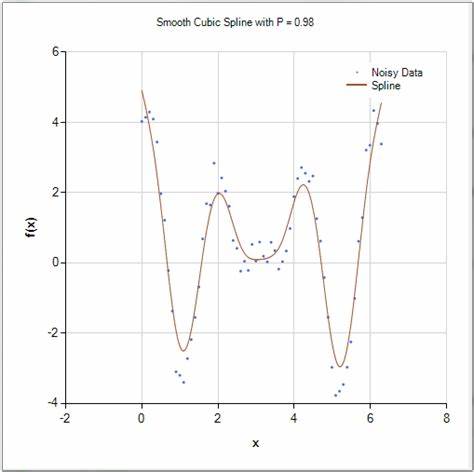
近年来,Transformer模型在自然语言处理、计算机视觉和多模态学习等领域引发了革命性变革,其核心组件Attention机制的独特作用广受关注。最新的研究成果表明,Attention模块不仅是深度学习中的关键技术点,其本质竟然可以被理解为一种平滑的三次样条函数。这一发现不仅为研究者提供了新的理论视角,也打开了将经典数值分析理论与现代人工智能技术结合的新大门。Attention机制初次被提出时,主要强调其在捕捉长距离依赖关系和动态权重调整上的优势,但其数学结构和形式并未得到充分揭示。最新研究明确指出,利用带ReLU激活函数的结构,Attention模块实际上是一个三次样条。三次样条是一种在数值分析和计算机辅助几何设计中广泛应用的分段多项式,具有连续二阶导数的特性,能够实现数据的平滑逼近与插值。
通过这种数学映射,Transformer内部的多个Attention层,包含Masked Attention和Encoder-Decoder Attention,也能被统一理解为三次样条的变体。Transformer中的非线性激活函数是实现这种样条性质的关键。具体而言,ReLU激活促使Attention表现为分段线性的结构,而这些分段线性结构组合起来,便形成了三次样条的框架。更进一步,将ReLU替换为光滑的激活函数如SoftMax,则能够产生平滑的、无穷可微的函数版本,也即"平滑三次样条",这与Transformer原始架构所采用的SoftMax Attention高度契合。这不仅为Transformer的设计和优化提供了理论基础,还解释了其在训练稳定性和泛化能力上的优越表现。从理论数学角度出发,假如接受著名的Pierce-Birkhoff猜想,则每一个三次样条都可以被构造为带有ReLU激活的Encoder模块的形式。
这种双向联系极大地丰富了对Transformer结构的理解,意味着Transformer不仅是深度神经网络的一个实验创新,更具备深厚的数学根基和极佳的可解释性。理解Attention作为平滑三次样条的意义,不仅限于理论美感。它在提升模型设计合理性、优化算法性能和增强计算效率方面都有实际价值。例如,利用三次样条的插值与逼近性质,研究人员可以设计更精细的Attention权重调整策略,减少模型对海量数据的依赖,提升模型的训练速度和推理准确度。此外,考虑到三次样条在计算机图形学的广泛应用,新的算法思路也可能催生Transformer在视觉任务上的创新变种。值得关注的是,将深度学习模块与传统数值方法结合,不仅能推动算法性能提升,还能改善模型的可解释性问题。
当前深度学习的"黑箱"特性是制约其广泛应用的瓶颈之一,而视Attention为平滑三次样条,则可将其抽象成数学上易于分析的对象,方便研究者理解模型内部机制和潜在局限,进而指导更合理的模型架构设计和训练策略。除此之外,平滑三次样条的数学框架也有助于Transformer的理论收敛性和稳定性分析,为未来的理论突破奠定坚实基础。随着人工智能应用的不断深入,Transformer已经成为自然语言处理和其他更新领域的标配工具。深入了解其核心Attention模块的底层数学结构,有助于推动该技术进一步发展。未来,基于平滑三次样条理论的Transformer模型优化、定制化设计和高效实现,必将成为研究热点和实际创新的源泉。总结来看,将Attention视作平滑三次样条为深度学习社区带来了融合经典数学与现代计算的全新视角。
通过这种理解,不仅强化了Transformer模型的理论根基,也为提升其性能与解释力开辟新道路。展望未来,在这个基础上深入发掘数值分析与机器学习的交叉创新,将进一步加速人工智能的技术进步和应用拓展,推动这个领域迈向更加成熟和广泛普及的阶段。 。