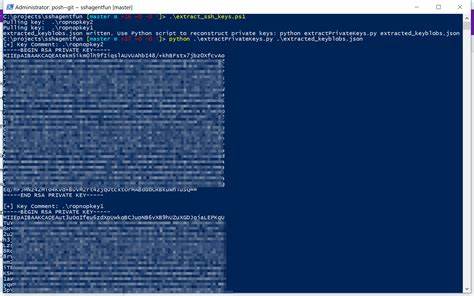
随着人工智能技术的快速发展,越来越多的语言模型被广泛应用于各类场景,从日常交流到专业技术辅助。然而,随着模型规模的扩大和训练数据的多样化,一些潜在的安全隐患开始浮现出来。其中,私密SSH密钥意外出现在AI训练数据中引发的安全问题,成为业界关注的热点。SSH密钥作为连接服务器和用户之间的安全桥梁,其私钥一旦泄露,可能导致严重的网络安全事件,甚至造成数据丢失或系统被入侵。今天,我们将系统探讨Claude训练数据中私密SSH密钥被提取这一现象的来龙去脉,分析其中的风险及背后的原因,并提出避免类似情况发生的措施。 在一次与Claude(Sonnet 4版本)的交互中,有用户意外发现模型能够输出完整格式的OpenSSH私钥示例。
尽管模型在察觉到用户输入极可能涉及私钥的敏感内容时,作出了提醒和阻止,但模型仍旧在后续对话中生成了格式完全符合真实SSH私钥的文本片段。经过验证,这段示例密钥能够通过标准工具ssh-keygen进行形式验证,显示其结构与一个2048位RSA密钥完全一致。这一事件瞬间引发了业界对大规模语言模型训练数据中含有敏感安全信息的担忧。 为何训练数据中会存在私密SSH密钥?根本原因在于训练数据的多元来源。为了提升模型的泛化能力与知识覆盖面,训练数据往往来自公开互联网文本、开源代码仓库、论坛帖子、博客内容等多种渠道。这些渠道中,很难避免存在用户无意或不慎暴露的私钥片段,尤其是在代码分享、运维手册、技术讲解等内容里。
此外,部分用户在网络上发布的示范密钥或测试密钥,如果格式接近真实密钥,也有可能被模型误当成可学习的有效信息。 与此同时,许多大型语言模型具备强大的“记忆”能力,能够复现训练中见过的长文本段落。当模型被询问与密钥格式相关的问题,或者受到类似提示时,可能会“复述”训练中学习到的密钥文本,哪怕这些内容原本在公开场景中是被禁止分享的。这样的行为暴露了语言模型在数据过滤和安全隐私保护上的巨大挑战。 这类事件暴露的风险不容小觑。若攻击者通过对话方式诱导模型输出真实私密密钥,便可能导致密钥泄漏,从而间接获得系统访问权限,对目标服务器发动攻击。
虽然此次示例密钥是演示用例,且经过确认并非真实可用密钥,但足以说明模型在内容控制上的漏洞,且未来完全真实密钥的出现风险无法根除。尤其是在模型迭代更新和数据集扩增时,如果敏感数据清洗不彻底,将继续带来隐患。 对个人和企业用户而言,保护私密安全信息的重要性进一步凸显。防止秘密密钥泄露从根本上避免灾难性安全事故,是信息安全管理的核心之一。企业在使用语言模型辅助开发、运维时,应当严格制定数据审核和使用规范,避免将真实敏感信息输入模型。同时,应建设完善的密钥管理策略,包括定期更换密钥、启用多因素认证、限制密钥权限和严格访问控制等手段,将泄露风险降到最低。
此外,AI模型开发者也必须高度重视训练数据的安全审查。针对可能存在的敏感信息,建立自动化检测机制及人工复核流程,确保所有私密凭证都在训练前被有效去除或替换。通过数据脱敏处理,减少隐私泄露的可能性,为模型的安全应用提供保障。同样重要的是,模型需在生成文本时引入更强的安全过滤和异常检测,避免明文生成敏感密钥内容。 技术社区对此问题也持续关注,已有部分研究尝试通过模型蒸馏、频率限制、生成内容审计等方式减少模型对训练数据记忆的依赖,限制其可能输出的敏感信息范围。未来,结合联邦学习、差分隐私等先进隐私保护技术,有望进一步提升模型训练和发布的安全性,防止私钥等高风险信息泄露。
总结来看,语言模型因训练过程包含大量公开数据,难免带入部分敏感字符和格式信息,像SSH私钥这类高安全级别的凭证尤为需要额外防护。亟需对训练数据进行严密筛查与脱敏,同时强化模型生成过程的过滤机制,推动相关行业制定统一的安全标准和操作规范。只有在技术落实和管理制度的双重保障下,用户才能放心构建及使用大型语言模型,从而充分释放其在生产效率和智能化领域的巨大潜力。 信息安全风险无处不在,尤其是在AI智能时代,数据合规和隐私保护成为不可回避的命题。通过不断完善训练数据处理流程,强化密钥管理意识,以及推动技术创新防线,才能有效抵御潜在威胁,确保数字时代的安全可信。Claude训练数据中私密SSH密钥意外暴露事件为业界敲响警钟,呼吁整个AI社区以更审慎的态度面对数据安全,切实保障用户与业务的数字安全基石。
。