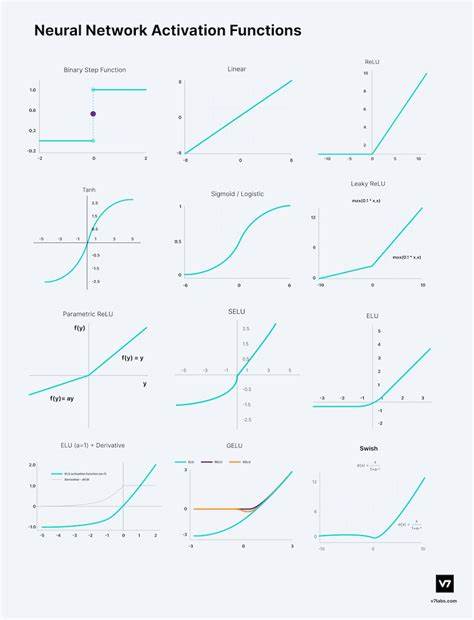
激活函数是神经网络中的核心元素,它们通过将每个神经元的输入信号转换为输出信号,赋予网络以处理复杂非线性问题的能力。没有激活函数,网络只会进行线性映射,无论堆叠多少层,也无法正确拟合现实世界中复杂的模式。随着深度学习的兴起,激活函数的重要性与影响力日益突出,成为提升模型性能和稳定性的关键技术。激活函数不仅决定了输出的范围和特性,还影响梯度的传递效果,从而直接影响训练速度和最终模型的泛化能力。当前,深度学习领域涌现了众多激活函数,从传统的Sigmoid和Tanh,到广泛应用的ReLU及其多种变体,再到近年来备受瞩目的Swish、GELU和Mish等现代函数。本文将详细介绍激活函数的基础知识、分类、数学特性及典型应用,探讨如何根据任务需求选择合适的激活函数以优化模型表现。
激活函数的设计目标,通常是引入非线性以突破线性的局限,同时保证梯度在反向传播中有效传递。以Sigmoid函数为例,它能将输入压缩到0到1之间,适合作为概率输出使用,特别是在二分类问题中非常流行。然而,Sigmoid在输入值极大或极小时,梯度几乎消失,导致训练深层网络困难,这是所谓的梯度消失问题。相较而言,Tanh函数输出在-1到1之间,具备零中心化特性,使得数据分布更平衡,能加速优化过程,特别适合循环神经网络等对上下文敏感的应用场景。随着计算性能的提升,ReLU函数因其运算简洁且梯度非零,从而极大提高了深层网络训练的效率,成为现代卷积神经网络的主流选择。ReLU将所有负值置零,正值保持不变,使激活稀疏化,降低计算复杂度。
但这种"死亡"现象即部分神经元永远不激活,也成为其不足之处,催生了Leaky ReLU、PReLU、ELU等变体,这些变体通过允许负区间有少量激活值来缓解神经元死亡,提升梯度流畅度和收敛速度。近年来,随着Transformer架构在自然语言处理和计算机视觉中的突破,GELU激活函数被广泛采用。GELU基于高斯累计分布的概率机制,对输入进行平滑门控,既保留了ReLU的非线性优势,又在负区间具有柔和过渡,提升了训练稳定性和模型表达力。Swish激活函数作为自门控机制的代表,将输入值与其Sigmoid激活相乘,表现出非单调特性,实验证明,在非常深的神经网络中能带来准确率提升,尤其在图像识别领域表现优异。深度学习实践中,针对分类任务的输出层,经常采用Softmax激活处理多类别概率分布,确保输出符合概率约束,使得模型输出结果更具解释性和可操作性。Softmax通过指数运算和归一化处理,将任意实数向量转化为概率分布形式,通常配合交叉熵损失使用,实现多类别分类效果优化。
激活函数的合理使用直接影响模型性能和训练效率。以经典二分类为例,Sigmoid因其概率解释透明,是最常用的激活函数。对比之下,当面对对称数据分布或者需要加快训练速度时,Tanh可能更加合适。同时,随着网络深度增加,选择诸如ReLU或Swish这样的现代函数能够有效缓解梯度消失及网络退化问题,帮助网络更好地拟合复杂非线性关系。以实际应用为例,谷歌移动端视觉应用MobileNetV3采用h-Swish激活函数,在提升准确率的同时显著降低了延迟,为实时图像识别开辟了新路径。Ultralytics的对象检测算法YOLOv5中,SiLU(即Swish的一个变体)激活函数帮助模型在精度和推理速度上实现平衡,推动了自动驾驶和智能监控的发展。
医学领域中,使用SwiGLU激活改进的Retformer模型在视网膜成像中实现了阿尔茨海默症的早期检测,大幅增强了检测准确性和敏感度,推动了医疗图像精准诊断的进步。构建神经网络模型时,需要根据任务类型、数据特点、计算资源和性能目标,科学地选择激活函数。传统任务中,Sigmoid和Tanh依旧有其用武之地;而在大规模图像识别、自然语言处理和生成式模型中,ReLU及其变体、GELU、Swish等现代函数则表现更为出色。PyTorch等深度学习框架为开发者提供了丰富的激活函数支持,使得尝试和评估不同函数的效果变得便捷,同时结合可视化工具与性能监控,有助于迅速定位模型瓶颈,调整激活策略。除激活函数本身的选择,设计网络结构时合理搭配激活函数与归一化层、残差连接等技术手段,能够进一步提升模型训练的稳定性和表达能力。总结来看,激活函数作为神经网络学习能力的源泉,贯穿于网络设计、训练和优化的各个阶段。
不断发展的技术推动下,现代激活函数展现出强大的性能提升潜力,尤其在深层模型和复杂任务中效果显著。选择合适的激活函数,不仅能够加速模型收敛,提高准确性,还能降低计算资源消耗,提升模型的实用价值。未来,随着神经网络架构的多样化和任务复杂性的提升,激活函数的创新和优化仍将是深度学习研究与应用的重要方向。理解和掌握激活函数的原理、特点和适用场景,是每一位人工智能从业者迈向成功的必备技能。 。