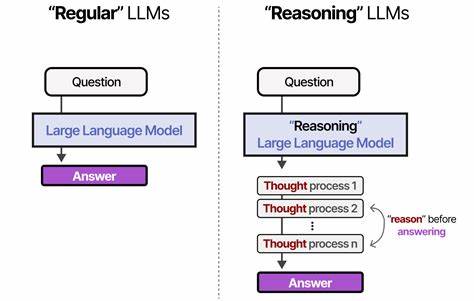
近年来,随着人工智能技术的迅猛发展,大型语言模型(Large Language Models,LLMs)凭借其强大的自然语言处理能力,成为了科技界和产业界的宠儿。其中,链式思维推理(Chain-of-Thought,简称CoT)作为一种能够引导模型系统化生成推理过程的技术,受到了广泛关注。它通过启发模型一步步地展开思考,显著提升了模型在复杂推理任务中的表现。然而,近期的研究显示,CoT推理并非一劳永逸,其实用性和稳定性存在较大争议。人们开始探问,所谓的链式思维推理真的是模型具备的"认知能力"吗?还是一种被训练数据局限的"幻象"? 探究这一问题的关键,在于理解模型如何通过训练数据学习推理方式。最新研究以数据分布的视角切入,提出CoT推理实质上是一种"有结构的归纳偏置"(structured inductive bias),这种偏置是模型在训练阶段从特定类型的数据中学习到的推理轨迹。
换言之,模型并非真正理解推理的本质,而是在面对与训练数据分布相似的任务时,能够条件式地生成类似于训练中观察到的推理过程。这种发现提醒我们,CoT的有效性在很大程度上依赖于训练数据与测试任务之间的分布匹配程度。一旦任务与训练样本存在较大差异,链式推理便变得脆弱甚至失效。 为了深入验证这一假设,研究团队设计了名为DataAlchemy的抽象可控环境,从零开始训练语言模型,系统性探查模型在不同数据分布条件下的行为。通过操控任务类型、推理步骤长度以及信息表达格式等多维度因素,实验结果揭示了CoT推理面临的诸多限制。这些实验证明,当模型面临在训练数据中未见过的推理模式或更长、更复杂的推理链时,其表现会显著下降,甚至完全失效。
换句话说,模型所谓的链式思维仅是拟合训练数据中出现推理轨迹的一种近似,而非源于对推理机制的真正认知。 这一结论对当前依赖CoT技术提升模型推理能力的研究和应用产生了重要影响。首先,它促使研究者重新审视大型语言模型的推理能力,警惕将训练数据中的模式泛化为普适推理能力的误区。其次,该视角为改进模型设计指明了方向:提升模型的通用推理能力,关键在于如何培养其适应更广泛数据分布的能力,而不仅仅是优化在特定训练集上的表现。这可能涉及创新的训练策略、更丰富和多样化的训练数据,以及引入基于逻辑及符号方法的推理模块,增强模型的推理泛化能力。 除此之外,CoT推理在格式和任务类型上的表现差异,也为实际应用提供了借鉴。
不同的任务结构和信息表达方式,会直接影响模型生成推理链的效果。这意味着,应用开发者在设计基于CoT的系统时,需要充分考虑目标任务的特性,避免在分布差异较大的场景中简单套用已有CoT策略。创新性的输入提示设计和任务调整或许能缓解部分分布偏差带来的影响,但根本解决问题仍需模型自身能力的突破。 近年来,伴随着算力的提升和预训练技术的进步,LLMs的体量和性能不断攀升,公众和业界对它们具备"人类级"推理能力的期望也水涨船高。然而研究显示,就目前技术状态而言,模型的推理能力更多表现为对训练数据中规律的统计学习,而非真正意义上的理解和逻辑推理。链式思维推理为我们提供了一个展示这种"拟人"推理过程的窗口,但这扇窗后面依然是一台巨大的语言模型在执行概率计算的机器。
展望未来,要实现真正通用且鲁棒的推理能力,人工智能研究者需要在多个方向持续发力。首先,提升模型训练数据的多样性和覆盖度,减少训练-测试分布偏差,是改善CoT推理可靠性的基础。其次,发展能够结合符号推理与神经网络学习优势的混合模型,将有助于建立更具解释力和泛化性的推理框架。此外,设计更高效的训练范式,如元学习和自监督推理路径探索,也可能促进模型获得更像人类那样灵活应对新任务的能力。 综上所述,链式思维推理作为大型语言模型重要的推理增强技术,展现了其在特定条件下提升任务性能的能力。但其背后本质是基于训练分布的模式匹配而非全面的逻辑推理,因而在分布发生变化时表现易受影响。
因此,CoT推理更多是一个充满潜力却依然具有局限性的现象。理解这种现象的本质,有助于科研人员明确未来改进目标,推动语言模型推理向更高阶、更通用的方向迈进。如此,走出"幻象",实现真正的智能推理,或许才是人工智能领域未来发展的制高点。 。