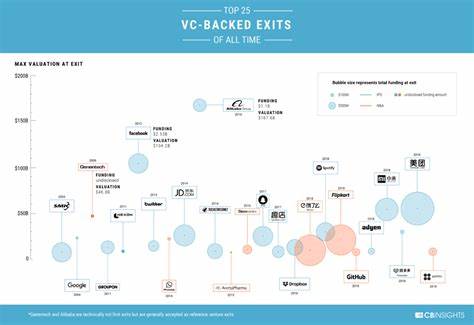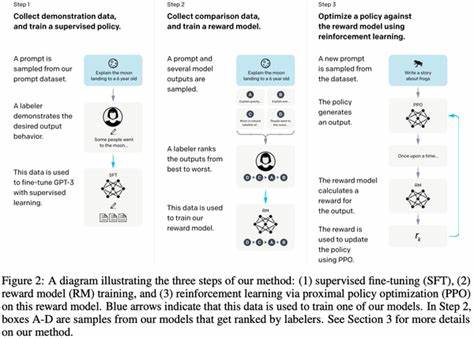
近年来,随着人工智能技术的快速进步,大型语言模型(LLM)如GPT-4和Claude成为推动自然语言处理领域的重要力量。它们能够完成诸如写作、代码生成、数据处理及辅助决策等多样化任务,极大地提高了工作效率和自动化水平。然而,在实际使用过程中,许多用户反映这些模型在遵循复杂指令时表现不够理想,存在一定的不确定性和不稳定性,这在实际应用中产生了诸多困扰和挑战。指令遵循能力是评估大型语言模型实用性的重要指标之一,特别是在涉及多步骤操作、严格格式要求或情感风格调控时,可靠且一致的输出显得尤为关键。当前的主流LLM虽然在语言理解和生成能力上取得显著突破,但由于本质是基于概率预测的模型,导致其难以完全避免忽略指令细节或产生变异性的输出。用户在尝试让模型避免特定词语、保持统一风格或精确遵守层级结构时,往往遇到重复修改和多次尝试才能得到理想结果。
对于需要长时间多会话操作的项目,模型还可能丢失先前输入的上下文或个性化偏好,进一步影响任务连续性和准确性。这种不稳定性不仅影响文字创作,在编程辅助、任务规划、结构化数据生成以及教学和研究等领域同样显现。举例来说,要求模型将纯文本转换为符合规范的表格时,模型常出现遗漏条目或格式混乱的问题,迫使用户需投入额外的验证和修正工作。在代码生成方面,虽然模型能完成复杂算法的编写,却可能因为未完全理解附加的细节约束而生成不符合预期的代码片段。面对此类挑战,部分用户和开发者尝试通过代码执行的方式增强结果的确定性,使生成内容更具重复性和自动化验证能力。此外,基于检索增强生成(RAG)和强化学习的技术也被引入,以期通过辅助机制提升模型对指令的精准把控和长期记忆能力。
尽管如此,现有解决方案仍然未能根本消除指令执行偏差,尤其在商业场景中,用户对准确、一致且可复现输出的需求日益迫切。业内专家认为,构建在大型语言模型之上的额外“约束层”或规则引擎,可以有效帮助用户设定并强制执行硬性规范,例如语调控制、逻辑严密性、格式严格性和任务目标的持续维护。这种扩展层不仅能减少人为重复确认的时间,也提升了跨会话的连贯性与记忆保留。当前,围绕这一痛点,市场呈现出明显的需求缺口,推动了创业者设计定制化的解决方案,力图突破传统大模型仅凭提示词预测的局限性。虽然主流LLM服务提供商正在不断优化模型结构和训练方法,致力于降低输出的随机性和提升指令理解度,但从用户反馈和应用效果来看,完全可靠的指令遵循还远未实现。未来,深度集成多模态数据,结合符号推理与神经网络相融合的混合智能框架,可能是提升指令遵守性的关键方向。
与此同时,持久化上下文记忆、多轮任务管理和自适应反馈机制将成为实现高度稳定与符合标准输出的基石。从商业角度看,如果能开发出能够精确定义并强制执行用户规则的语言模型工具,将极大提升企业级应用的精准度与效率,促进AI工具在医疗、法律、教育和金融等对合规性要求极高领域的落地普及。用户愿意为更加可靠、可控且记忆持久的LLM解决方案付费,表明市场潜力巨大。总结来看,尽管目前大型语言模型在广泛应用中已表现出强大的语言理解和生成能力,但指令遵循的可靠性依然是制约其全面实用化的核心难题。通过开发辅助层面解决方案和推动技术创新,有望显著提升模型的稳定性和一致性,为用户带来更好的使用体验和更高的工作效能。未来几年内,随着算法进步和产业投入加大,指令遵循困难将逐步缓解,LLM的普及与应用也将迈向更高层次,助推人工智能真正实现从工具向合作伙伴的转变。
。