在当前深度学习的发展浪潮中,注意力机制尤其是稀疏注意力方法的优化成为提升模型性能和效率的关键。DeepSeek提出的Native Sparse Attention(NSA)作为一个代表性的稀疏注意力方案,借助动态稀疏和高效内存访问设计,在GPU平台展现出卓越表现。然而,由于TPU与GPU在架构设计以及执行流水线上的根本差异,如何有效将NSA迁移并优化到TPU平台成为了一个不容忽视的挑战。本文将详细探讨NSA算法在TPU上的实现过程,面临的技术难题以及创新应对策略,旨在为稀疏注意力的高性能计算提供宝贵经验。首先,我们需要直观理解NSA为何能在GPU上取得高效性能,这其中动态稀疏性的实现和系统级的高TensorCore利用率是核心优势。NSA采用了基于指针的动态内存加载策略,使得仅聚焦于top-K重要的块进行计算,这种选择性访问有效减少了无用计算。
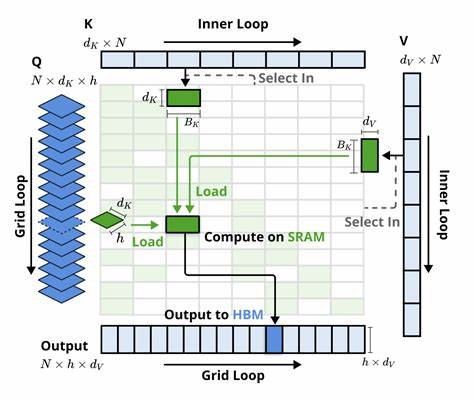
GPU擅长处理这种指针跳转和并行化排序(如bitonic sort),为动态选择带来了天然便利。除此之外,NSA设计了组级分块(tile)机制,以保证矩阵乘积的维度足够大,从而最大化TensorCore资源的利用率,这一点让内核性能近乎发挥到极致。相较GPU架构,TPU作为一种专为张量计算打造的加速器,内部执行依赖定制的MXU矩阵乘法单元,其流水线和内存访问方式更有序且倾向大块连续数据访问。这里的本质冲突在于:NSA动态稀疏带来的非连续、非单调的内存访问与TPU线程模型的固有顺序遍历不匹配。JAX/XLA编译器对动态索引的支持较为有限,Pallas这类TPU的底层内核编程模型则严格要求在预定义的、有序的索引路径中执行。因此,实现NSA中的top-K选择并按动态顺序访问选中块,必然导致性能瓶颈。
为解决这一矛盾,研究者提出依托软最大化(softmax)的顺序不变性,对选中块索引进行排序,从而转换成单调递增访问序列。这样,TPU可以按顺序加载并处理数据,同时数学上的在线softmax机制确保结果的正确和数值稳定。虽然这种处理带来一定的数值精度挑战,特别是在低位宽计算(FP8及以下)中,但结合FP32累积和BF16存储,能够在很大程度上规避溢出与下溢问题,保证最终计算准确性。另一大挑战源自NSA中设置的滑动窗口式块采样,块间存在大量元素重叠。TPU内核通常期望格定非重叠内存块以便高效执行,但NSA的重叠块设计若简单逐块加载,必然导致重复访问,严重浪费带宽和计算资源。面对这一情况,提出了"聚簇稀疏切片"(Clustered Sparse Tiling)策略,利用NSA的空间局部性假设,将接近的多个选中块进行聚合处理,打包成较大且连续的数据块。
这样不仅降低了冗余访问,也使得TPU的流水线能够充分发挥大块连续数据的优势,有效提升了算力利用率。值得注意的是,TPU的多个内存层级(HBM、VMEM、VREG)之间复杂的数据传输机制对内核设计也提出了更高要求。Pallas引入的标量预取(Scalar Prefetch)技术为流程优化带来了利器,通过只加载必要数据来避免无谓的内存访问。但受制于编译器切片限制,预取操作的切片大小需求必须是静态常量,进一步限制了灵活性。该限制与NSA预先定义的块大小及步长相契合,刚好成为一种优势,从而实现高效的动态数据调度。为保证流水线的最大效率,生成高效的预取映射(Prefetch Map)极为关键。
由于预取计划依赖动态稀疏且存在反向依赖,传统的顺序计算耗时且难以扩展。创新性地,将该问题转化为前缀扫描(Prefix Scan)形式,以最小值关联操作实现了并行化处理,极大地优化了预取表的构造。这种策略不仅兼容JAX的向量化和扫描操作,还能够通过使用哨兵值过滤无效加载,实现稀疏数据的高效流水线调度。在实际性能评测场景下,经过上述优化的TPU Pallas内核,相较于向量化JAX基线,获得了约2.5倍的速度提升。更重要的是,显著降低了内存压力,实现了中间矩阵不再完整物化,提升了带宽利用率和计算密度。数值验证表明,该方案在BF16数据类型下能实现极佳的近似精度,展现出在线softmax与FP32累加的良好配合。
然而,对于长序列输入和多查询批次的GPU常见并行优势,TPU内核仍然表现有限。具体表现出MXU/ VPU资源未能充分利用,矩阵乘法趋于向量乘法,流水线吞吐未达预期。这一问题部分源于实验合成数据中缺乏NSA模型训练中常见的关注块聚簇分布,限制了流水线负载均衡。针对批处理查询的设计,也面临诸多挑战,如计算代价高昂的预取映射、不同查询间关注块选择不重叠引发的流水线低效等。设计适合TPU的查询合并策略(如"联合查询切片")成为后续工作重点,希望通过利用查询间的局部相似性,减少所需加载块的总量,从而进一步提升流水线效率和资源利用。此外,由于早期Pallas版本及TPUv2的共享内存较小,对预取映射的存储也有限制。
针对长序列及较大预取映射,研究者通过将部分索引数据压缩为uint16并按需升扩展至int32,有效减小了显存开销,避免了共享内存溢出问题。这种权衡保证了大规模场景下的应用可行性。展望未来,NSA算法在TPU上的优化还存在诸多可探索空间。确定块大小、选择块数量及步长对模型训练表现和推理效率影响密切,合理调整需要结合训练与硬件的协同设计。伺机设计更智能的查询批处理机制也将显著释放TPU算力潜力。总的来说,NSA算法以其独特的动态稀疏设计和高效的底层运算安排,在GPU平台表现优异。
但TPU的独特硬件特点以及Pallas核心编程模型的限制,迫使我们必须重新审视内存访问和计算流水线,采用排序转化、聚簇切片与高效预取策略相结合的技术路线。此次针对NSA的TPU优化尝试,不仅为未来稀疏注意力的硬件加速树立了范例,更揭示了现代大规模机器学习模型优化所面临的硬件-软件协同复杂性。通过详细工作记录和开源代码共享,研究者鼓励社区共同推进TPU上稀疏注意力的高效实现,助力深度学习推理与训练迈向更高性能与更低能耗。 。