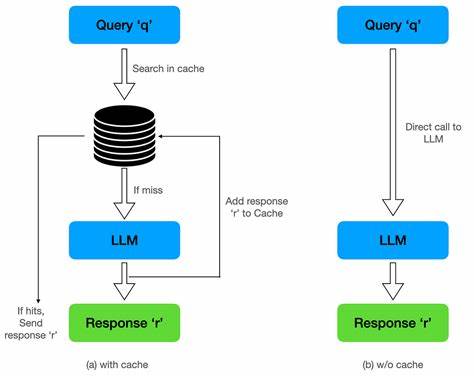
近年来,随着大型语言模型(LLM)在自然语言处理领域的迅猛发展,越来越多的应用开始依赖这类模型提供实时的智能交互服务。无论是智能问答、自动写作还是对话机器人,提高系统的响应速度始终是使用体验的关键所在。提示缓存(prompt caching)作为主流LLM接口提供商诸如OpenAI、Anthropic、Gemini等普遍采用的优化技术,被广泛认为可以显著降低推理成本并提升响应速度。然而,实际使用过程中,许多开发者发现提示缓存并不能彻底解决延迟问题,特别是在时间到首字节(TTFT, Time To First Token)方面。那么,为什么提示缓存未能满足我们对低延迟的期待?本文将带您深入剖析提示缓存的本质、其技术实现原理及限制,进而揭示影响延迟的核心因素。 提示缓存的工作原理相对直观。
用户将一段文本输入模型作为提示,模型基于该提示生成后续内容。传统上,每次调用模型时,输入的所有文本都会重新处理,耗费大量计算资源。提示缓存技术通过在模型计算过程中保存关键状态(具体为注意力机制中的键值对矩阵缓存,通常称为KV缓存),使得后续对相同提示的请求无需重新计算已处理的部分,从而降低了输入令牌的成本并优化了响应速度。举例来说,如果您将某本书《强化学习导论》全文缓存,后续针对书中内容的多个提问便能减少重复计算和成本,响应速度也将获得一定提升。 然而,现实体验中,尽管KV缓存有效减少了成本,但时间到首字节依然会因缓存规模增长而呈线性增长趋势。背后的核心原因在于Transformer模型中注意力机制的工作方式。
Transformer的注意力计算涉及查询矩阵Q与键矩阵K之间的点积操作,其中K和V(值矩阵)会随着输入序列长度线性增长。具体来说,当模型解码第n个令牌时,除了计算该令牌的查询向量Q外,还需要将其与所有之前序列的键矩阵K做乘积。此时,尽管之前的键值对已经缓存,但随着序列长度增加,计算QKᵀ的负载依然在线性增长,无法避免。 此外,KV缓存的加载也非零代价。缓存数据依赖显存(如GPU的高速缓存),较大缓存会占用更多显存带宽和时间,进而影响整体的延迟表现。即使缓存已经加载完毕,进行注意力计算时的矩阵乘法依旧会受到序列长度的影响。
这意味着提示缓存带来的速度优势更多是在整体计算资源投入和成本上的缩减,而不是对响应时间的根本提升。 实验数据进一步验证了这一点。以Qwen2.5-14B模型为例,使用先进的Attention实现(FlashAttention-2)后,时间到首字节随着上下文令牌数每增加10000个,平均会增加约4.69毫秒。尽管看似增加幅度不大,但在实际应用中,当需要处理数万甚至更多令牌的长上下文时,累计的延迟依然显著。这种趋势具有普适性,适用于大多数采用全连接、非局部注意力的Transformer模型。 理解这些技术细节后,我们可以明确,提示缓存的价值主要体现在减少重复计算和API调用成本。
对于追求极低时间到首字节的场景,单靠提示缓存不足以满足需求。开发者需要结合其他技术手段加以优化。例如,采用稀疏注意力、局部注意力或多头潜在注意力等先进注意力机制,可以有效降低序列长度对计算复杂度的影响。此外,分布式计算、模型剪枝、量化和专用硬件加速,也能在不同层面提升响应速度。 对于应用设计者而言,优化策略还应涵盖前端设计和交互流程,包括限制输入长度、分段处理长文本、增加用户输入提示引导,最大限度地在用户体验与模型性能间取得平衡。同时,清晰了解缓存与延迟的区别以及模型底层机制,有助于正确设定性能预期,避免盲目依赖单一技术而忽视系统真实瓶颈。
综合来看,提示缓存是一项显著提升成本效率的技术创新,极大节省了计算资源并降低了推理成本,但它并非解决LLM响应延迟的灵丹妙药。其固有的结构性限制决定了延迟仍然会随着上下文长度增长而攀升。要实现更低延迟、更流畅的交互体验,技术开发者必须融合多种优化方法,从模型架构创新、硬件性能提升到前端交互设计进行系统性改进。 展望未来,随着注意力机制研究和硬件技术的不断推进,更高效的KV缓存管理方案、更智能的上下文选择算法以及更具针对性的优化技术将不断涌现。对LLM应用而言,理解和适应这些变化,将是提升用户体验和保持竞争优势的关键。 。