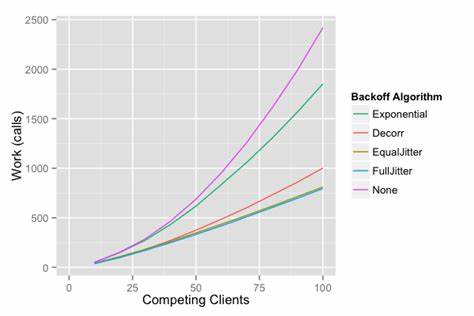
随着互联网和分布式系统的普及,软件服务之间频繁依赖外部资源和第三方接口,面对网络故障、服务宕机等不可避免的错误,合理的重试机制成为保障系统稳定的重要手段。指数退避作为一种经典的失败重试策略,通过每次失败后等待时间成倍增加,试图减少对失效服务的请求压力,降低资源浪费。然而,尽管指数退避听起来颇具逻辑魅力,其实际应用中存在若干显著缺点,可能导致用户体验下降和系统恢复延迟。本文将对指数退避的弊端展开深入分析,并提供更符合现代计算环境的改进建议。 首先,指数退避的根本问题在于它可能导致系统长时间处于等待状态。这种策略在服务出现故障的初期,重试间隔较短,尝试重新连接相对频繁;但随着失败次数的增加,重试间隔迅速延长,期间系统处于“睡眠”状态。
当外部依赖服务重新上线时,应用程序可能仍处于较长的等待期内,未能及时恢复正常请求流程,从而延长整体服务中断时间。例如,假设一个服务宕机一个小时,应用按照指数退避策略重试,可能最终导致应用自身最长等待时间接近两小时。这种时间延长对用户体验造成严重影响,而用户往往无法理解为何问题明明被解决,服务仍不可用。 其次,指数退避使故障排查变得复杂。运维人员在修复底层服务后,期望依赖方迅速恢复正常工作。但是由于指数退避带来的长时间等待,依赖服务的恢复并不会立刻反映到上层服务。
调试人员因而常常陷入困惑,误以为上层服务依旧存在问题,浪费大量时间和资源进行排错,推迟整体系统恢复时间。更糟的是,经过多次大幅度等待后,对系统重启成为唯一的解决方案,打破了自动恢复的目标。 更加令人关注的是,指数退避在多层服务依赖链中会造成时间延迟的几何级增长。假设服务A依赖服务B,服务B再依赖服务C,如果服务C出现故障,并且各层均采用指数退避策略,重试延迟将在每层叠加。这样的延迟累积意味着即使底层问题解决,上层服务恢复需要更长时间,带来指数级的总体中断时间。这种叠加效应大幅降低了系统整体的弹性和可靠性,也增加了业务中断的风险。
当前硬件和计算资源成本持续降低,系统计算能力提升明显,这使得需要通过长时间减少重试频率以保护资源的动机有所弱化。在许多实际应用场景中,采用较短且固定的重试间隔,甚至结合有限的随机抖动,能够更有效地平衡资源消耗与恢复速度。合理设定固定等待时间可以保持系统活跃地检测依赖服务的恢复状态,提升服务响应速度,避免不必要的性能浪费。 理想的重试机制应该避免无限增长的等待时间,上限应该限定在用户无法察觉的短时间范围内。指数退避加上明确的最大等待间隔限制,能够部分缓解问题,但仍不如采用恒定或自适应但受限的重试间隔灵活。保证在依赖服务修复后的极短时间内尝试恢复服务,是提升整体系统健壮性的重要手段。
此外,对于开发者而言,设计重试策略时还应考虑应用场景和用户需求。对于某些实时性要求极高的业务,长时间沉睡显然无法接受;而对于批处理或不频繁请求的后台任务,可适度调优等待间隔,但仍需避免不合理的增长。现有一些更为现代的算法通过基于服务健康检测的反馈机制动态调整重试间隔,既保证了不浪费资源,也能快速响应故障恢复。 从根本上说,指数退避的理念源自于试图避免对不稳定服务的“疯狂”请求,防止雪崩效应以及过载情况。然而,现实中服务崩溃修复通常发生得相对快速且不可预测,盲目等待更长时间,反而延误了恢复。软硬件资源充裕的今天,适度增加重试频率并配合合理的间隔时间和上限,往往能实现更好的平衡。
最后,服务的自动化监控和异常检测能力同样至关重要。重试机制只是保障系统稳定的一个环节,更高级的策略应包含服务健康状态实时采集、智能报警及自动化恢复方案,减少人为介入,缩短故障对业务的影响时间。对重试机制的反思和优化,是迈向更鲁棒微服务架构和高可用系统建设的重要课题。 总结来看,指数退避作为经典的故障重试策略,虽然理念优美且在某些场景下有效,但其带来的长时间等待、排查困难和多层服务的时间叠加问题,影响了服务的快速恢复和用户体验。现今计算资源充裕且服务间复杂依赖普遍存在,开发者应重新审视指数退避的适用性,采用恒定或有界的重试间隔结合智能检测,提升系统恢复效率。未来,高效的重试策略将会成为保障服务稳定和持续交付的关键环节。
。