大型语言模型(LLM)如GPT系列的出现,极大推动了人工智能技术的发展,使得机器在理解和生成自然语言时表现出前所未有的能力。然而,尽管这些模型具备强大的预训练能力,用户在实际应用时常常面临记忆特定数据或应对庞大代码库的挑战。尤其是在需要频繁查询特定知识领域或大型代码仓库的场景下,如何让模型更好地理解和“记住”相关信息,成为目前讨论的热点话题。 微调(Fine-tuning)是针对预训练模型进行额外训练,使模型更好地适应特定任务或数据的常用方法。它通过在已有的语言模型基础上,加入新数据进行梯度更新,强化模型对特定内容的掌握。这种方法不仅能提升模型在特定领域的准确性,也可大幅改善生成结果的相关性与上下文理解能力。
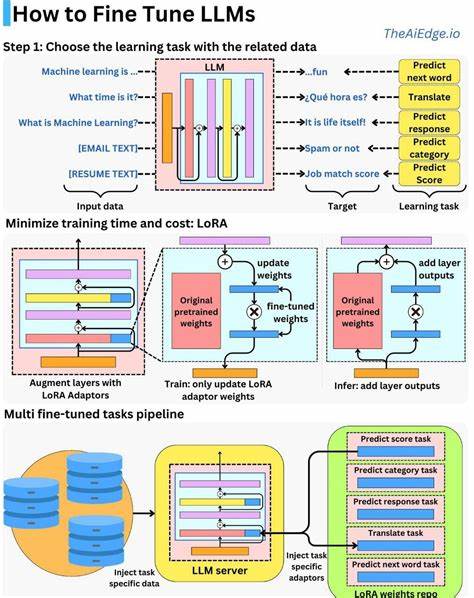
那么,是否可以通过微调让大型语言模型“记住”你指定的数据?答案是肯定的,但要结合具体需求理解其局限性和最佳实践。微调绝对是一种可行的技术,能够让模型在面对该特定数据时表现更好,减少依赖于提示中频繁重复输入大段上下文。但这并不意味着将所有要记忆的数据都放入模型权重中,而是需要合理选择和处理数据,保证微调过程的有效性和稳定性。 面对庞大代码库的场景尤其如此。大型代码库往往包含数百万行代码,甚至多个项目组成,传统的将全量代码作为模型输入的方式不可行,因为主流语言模型的上下文窗口存在限制,通常在数千甚至上万的Token上下。将所有代码直接放进提示中,既超出模型承载能力,也严重影响响应速度和费用成本。
由此,开发者开始关注迁移学习、增量学习和检索增强生成(RAG)等多种技术手段。迁移学习的微调方法之所以被关注,是因为它允许模型在保留原有语言理解能力的基础上,针对特定代码库进行适应和优化。通过选择结构化、高质量的代码片段进行微调训练,并结合标签注释,有助于模型形成对该项目的深入理解。 检索增强生成(Retrieval-Augmented Generation)则是解决超大数据量访问的另一种有效策略。它结合外部知识库或向量数据库,在模型生成答案时先检索最相关的上下文段落,进而生成回答。该方法意味着不必将所有数据纳入模型参数,而是实现模型与外部记忆库的协同工作。
比如把代码转化为向量索引,实时查询相关代码片段,模型则在此基础上回答问题,大大突破了上下文窗口限制。 还有高效的处理方式是通过“分块”和“摘要”技术,将大规模代码拆分成结构合理的小块,对核心模块进行摘要归纳。微调和提示中均可结合这些相对精炼的代码表示,提升模型对于大型项目整体架构和逻辑的理解效果。 尽管微调和上述技术的优势明显,但也并非完美无缺。微调通常成本较高,训练时间和算力需求较大,且频繁更新模型参数会带来版本管理和模型漂移等挑战。另外,在敏感或私有数据的场景下,微调也有潜在泄露风险,必须确保数据安全和合规管理。
鉴于此,实际应用中推荐根据需求平衡微调与非微调方法。对于极其重要且稳定的代码库,进行一次或数次微调来固化相关知识十分有益。而对于频繁迭代变化的项目,更多采用检索增强策略,结合最新版本的代码索引,实现动态、高效的知识访问是更优选择。 此外,业界近年还在探索参数高效微调方法,如LoRA、Prefix Tuning等,力图减少微调对计算资源的需求,同时保证适应性。这些方法将有望降低微调门槛,使个性化记忆的定制更加普及。 总结来看,大型语言模型确实可以微调以记忆特定数据,尤其是针对大型代码库,通过微调结合检索技术,可以有效绕过上下文窗口的限制,提升模型在特定任务中的表现。
关注微调方法的进展,配合动态检索体系,开发者和企业可以更灵活地利用LLM自动化和智能化地管理和利用海量代码资产。未来,随着算法和硬件的不断优化,结合个性化训练和即时检索的混合方案,将成为提升大型语言模型记忆力和实用性的主流趋势。