近年来,随着人工智能技术的飞速发展,智能对话系统和多模态交互模型被广泛应用于各类实际场景中。越来越多的系统设计中,模型不仅要理解自然语言,还需要调用特定的工具或接口来完成复杂任务。在这种背景下,一个看似简单却极具挑战性的问题浮出水面:人工智能模型是否能够准确地统计自己调用工具的次数?换言之,当模型被要求随机多次调用某个工具时,它是否清楚自己调用了多少次,并且能否正确反馈调用次数? 这一问题的提出与答案,直接影响到模型在复杂任务中的可靠性、透明度及用户体验。比如在多步骤推理、事务处理或资源管理场景中,工具调用的准确计数能够帮助系统合理分配资源、防止滥用以及进行有效的错误追踪。基于此,研究人员开展了相关实验以探究不同模型对工具调用次数的感知能力。 实验设计中,模型被要求以随机次数调用某个预定义工具,次数范围大致在1到100之间,完成调用后回答调用了几次。
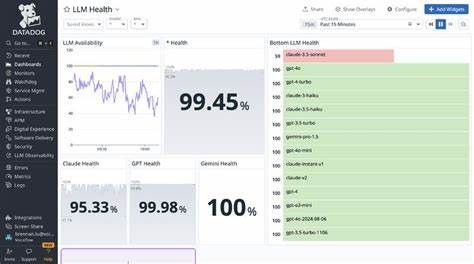
通过多次不同模型的重复实验,能够评估它们的准确率及模式偏好。实验涵盖了多种主流AI模型,包括不同版本的Claude系列、GPT-4及其迷你版,以及OpenAI的o系列模型。 实验结果显示,模型在工具调用次数的准确识别方面表现不一。部分版本如Claude 4 Opus和GPT-4.1表现出较高的准确率,能够在多次实验中准确报告调用次数,命中率接近甚至达到100%。这说明这些模型在保持状态追踪或内部计数方面有较为优秀的能力,能够较好地理解任务要求并结合自身上下文进行精确输出。 然而,也有部分模型表现欠佳。
例如Claude 4 Sonnet版本准确率为0%,显现出在此任务中明显的缺陷,常常错误估计调用次数。GPT-4o-mini和GPT-4.1-mini这类轻量或简化版本模型表现相对较弱,准确率波动较大,表明模型规模和复杂度可能正相关于它们对工具调用计数的能力。 从模型最常给出的调用次数版本来看,存在一定偏差和模式集中现象。例如某些模型大量倾向于输出固定数字,且其出现概率超高,说明模型在计数任务中有时更倾向于选择简单猜测而非真正的计量,这很可能是因为计数信息未被显性捕捉或者模型在中间状态管理上的限制。 这种情况的产生,部分源于当前模型设计的内在机制。大多数大规模语言模型擅长于生成连贯语言和推理,但并非专门设计用于精确记忆和数字计数。
他们的记忆能力多基于上下文窗口和概率分布,而非逐一记录事件的“计数器”。因此,在多次调用或重复动作的跟踪方面存在天然难题。 尽管如此,随着人工智能研究的深入,开发具备更强状态管理及记忆能力的模型成为可能。例如结合强化学习、长短时记忆网络、或者引入显式状态变量的模型版本,可增强对工具调用次数的准确把握。此外,模型与工具的桥接接口可以设计为反馈调用计数,协助模型进行确认和校准,减少误差。 这项能力的提升对众多行业应用意义重大。
金融行业中需要严格记录交易次数及调用外部风控工具;医疗诊断系统中模型调用辅助诊断工具的次数直接影响诊断流程与结果可靠性;智能客服系统中准确追踪工具调用频次有助于优化响应效率和用户满意度。 除技术层面的挑战外,工具调用次数的反馈还涉及模型解释性和透明度的提升。用户及开发者可以通过调用次数理解模型执行的具体细节,加强对系统行为的信任感。同时,准确的调用次数统计还能作为调优模型性能的重要指标,优化调用策略,实现更高效的资源利用。 基于目前实验数据,若需在实际系统中实现准确的工具调用计数机制,推荐使用已证实具备高准确率的模型版本或者通过辅助机制增强计数能力。此外,开发者应关注模型对计数任务的偏差倾向,通过多次验证实验选出最协调的组合方案。
未来,人工智能模型将进一步融合记忆增强和工具动态调用能力,支持更加复杂和多样的任务环境。模型本身对工具调用行为的感知将从零散模糊转向精准明确。这样的进步不仅满足技术需求,更能赋能更广泛的应用场景,包括自动化流程管理、智能助理、一体化办公环境等。 总之,模型是否知道自己调用工具的次数是AI能力细节中的关键一环。实验揭示当前主流模型在此任务上的强弱差异及可能成因,为模型设计和应用优化提供了宝贵参考。随着技术的不断迭代和突破,预计未来人工智能将在工具调用的跟踪与反馈方面展现出更卓越的表现,使得智能系统更可信、更高效亦更贴近人类需求。
通过深化研究和持续实践,推动智能模型与工具的无缝融合,将成为实现真正智能交互体验的核心目标。