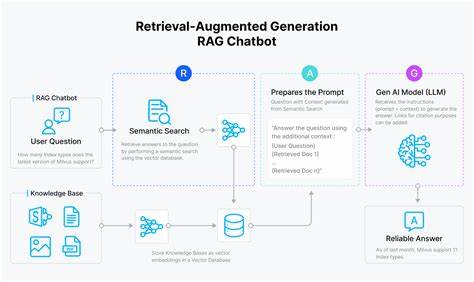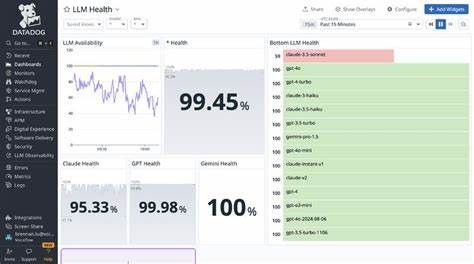
随着人工智能和大语言模型(LLM)技术的快速发展,越来越多企业将其应用于客户服务、内容生成、自动化流程等多种场景。然而,令人头疼的现实是,主流LLM服务商的稳定性仍然存在局限,频繁的服务中断成为阻碍企业稳定运营的隐形杀手。OpenAI和Anthropic等知名供应商的月度正常运行时间约为99.8%,这意味着每月存在数小时的潜在宕机时间,这在面向客户的关键应用中足以引发严重的业务中断和用户流失。应对这一挑战,企业必须超越被动等待供应商恢复,主动构建具有弹性和容错能力的系统架构,保障AI服务的连续可用性。 许多企业尝试通过人工介入实现服务供应商的切换,然而实际操作证明这一方式存在诸多弊端。首先,现代应用通常面向不同场景使用多种模型,人工执行全局切换时往往无法满足模型路由的细致需求,导致部分服务性能下降和混乱。
其次,人工切换的响应时间较长,从发现问题到完成响应往往需要数分钟甚至更久,这对于实时性要求极高的客户服务场景来说不可接受。更重要的是,将繁杂的故障分类和判断工作交给人力不仅效率低下,也极易因误判而导致切换不及时或切换过于频繁,反而加剧系统不稳定。 基于上述反思,领先企业纷纷引入自动化降级和故障切换机制,打造智能的多供应商冗余系统。在实践中,核心思想是根据不同应用需求和模型能力对模型进行分类管理,针对每类模型设计专属的优选供应商顺序。当主用服务不可用或响应超时,系统能够迅速切换到备选服务,无需人工干预,确保服务不中断。 具体来说,模型根据其特点和使用场景分为快速响应型、智能理解型和推理型等类别。
每个类别分配合适的模型与之对应,如快速类别优先采用响应速度快的轻量级模型,智能类别则使用理解能力较强的高级模型。供应商也会按照优先级排序,比如优先调用OpenAI,其次是Anthropic,然后是其他供应商。系统通过预设时间限制监控每次调用,当检测到错误或超时,立即切换至下一个优先级模型,保持服务的稳定输出。 在实现流式响应服务时,自动切换策略同样面临挑战。因为一旦开始向用户发送响应内容,后续无法再重新切换供应商,否则会造成内容断裂和用户体验下降。对此策略是在流式响应开始之前完成切换判断,确保在首个token输出前选择可用模型。
一旦开始输出,就保持当前通道直至完成,避免用户感知到异常。 这一简洁而高效的故障切换机制带来多重显著益处。首先,切换速度从以往数分钟降至数百毫秒,极大提升了系统的响应速度和稳定性,几乎消除了客户可见的服务中断。其次,系统自动处理部分性能下降以及短暂故障的情况,无需频繁手动切换,降低了运维负担和人工压力。同时,仍保留了人工调整供应商优先级的灵活性,用于持续优化延迟和服务质量。 当然,采用多供应商冗余策略也带来了额外的质量管理成本。
不同供应商模型在生成内容质量和风格上存在差异,单一的提示语需要针对多个模型进行验证,增加了开发和测试时间的投入。这推动企业加强自动化评估工具的开发,利用AI自身作为评价体系,实现跨供应商结果的快速一致性验证,提升整体验证效率。面对不常用的后备模型,企业则倾向于通过自动化手段替代人工全面评估,保持运维效率。 经过系统部署,企业在多个真实场景中实现了超过99.97%的有效正常运行时间,且在历史上多次大规模服务中断事件中,客户请求失败率低于0.001%。这一成绩长远保证了客户满意度和品牌声誉。更重要的是,自动化故障切换消除了运维人员的紧急压力,使团队能够专注于开发新功能和提升系统性能。
这场由被动等待供应商恢复向主动打造高可用AI系统的转变,彰显了优秀工程文化的力量。把供应商可靠性视为可控制、可解决的工程问题,推动多供应商自动切换等架构创新,极大增强了系统的弹性和可信赖性。企业客户将不再因为单个供应商的技术波动而受到业务影响,用户体验更加稳定流畅。 随着AI应用场景的日益拓展,企业还将继续探索容灾架构的新思路,例如通过分布式AI服务架构、多区域部署和实时性能监控等,实现对服务稳定性的全方位保障。同时,自动化评估与故障检测技术也在不断成熟,未来的智能切换系统将更为精准和高效。 当前,具备快速响应与智能故障切换能力的AI系统已成为行业标配,能够显著提升商业应用的韧性和用户信任。
企业若能抓住这一技术趋势,投资构建完善的多模型多供应商冗余机制,将在激烈竞争中获得核心优势。 未来,打造稳健的AI服务生态,真正实现“LLM服务商可能宕机,但您的系统绝不断线”的目标,依赖于持续的技术创新和工程实践的积累。只有这样,才能让客户体验始终如一,企业智能化转型道路更加平稳顺畅。