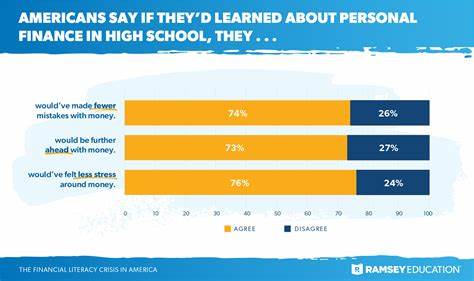
随着人工智能技术的飞速发展,基于大语言模型(LLM)的应用正日益普及于各类智能服务和产品中。对于这些应用而言,响应速度,尤其是模型生成第一个输出令牌的时间(即延迟),直接关系到用户体验的流畅度和整体服务质量。2025年10月发布的LLM延迟排行榜,揭示了各大云服务商在服务器无状态环境中,所提供大语言模型的延迟表现,为行业提供了重要的参考指标。了解这些数据背后的细节及其影响因素,有助于开发者和企业制定更优的技术方案,提升系统响应效率。排行榜基于"time-to-first-token"指标进行测量,即从请求发送到模型首次生成输出令牌所需时间。数据采集地点主要为欧洲中部,同时也在美国中部进行了验证,结果极其相似,显示出跨区域的一致性。
这种测量方法体现了应用实际体验,因用户最先关注模型何时开始回应,而非完全输出的时间。排行榜中的各模型均由不同云服务提供商托管,涵盖多种规模与能力规格。为了验证模型的稳定性和准确性,排行榜还引入了"通过率"指标,以一个简单的URL分类任务为子测试,控制最大生成令牌数,保证对比的公平性和实用性。观察发现,一些专注推理的模型因初始输出了诸如"<think>"标记而未通过测试,说明了模型预热和输出策略对稳定性的重要影响。延迟表现方面,当前领先的模型多基于优化过的架构和云端硬件环境,结合先进的负载均衡与缓存策略,实现了毫秒级别的响应速度。不论是在欧盟区域还是美洲,部分模型能够稳定保持较低的平均延迟,同时通过率也表现优异,体现出其可靠性与实用价值。
与此同时,排行榜揭示了模型规模与延迟之间的权衡。较大规模的模型虽然在理解和生成能力上更强,但往往需要消耗更多计算资源,导致响应时间延长。对此,有些云商采用了模型剪枝、量化和异构计算技术,显著改善了延迟表现;还有的通过分段生成策略减少首响应时间,从而优化用户交互体验。选择合适的云服务提供商和模型版本,是每个企业必须权衡的重要决策。榜单数据表明,某些服务商在特定模型上的延迟表现非常突出,适合对响应时间敏感的实时应用,如智能客服、语音助理等。而另一些则更注重生成内容的深度和多样性,适合复杂推理与内容创作场景。
除此之外,网络传输距离与带宽也是影响延迟的关键因素。虽然数据测量基于特定区域,但实际部署中,用户所在地与云端节点的地理位置布局,决定了数据包传输的效率。合理架构全球多区域部署方案,将显著降低因网络延迟带来的性能瓶颈。开发者还需关注模型预热时间和冷启动延迟的问题。传统的无状态服务器模型容易面临首次请求延迟较高的挑战。为此,有的云服务商引入了持久化连接和预加载机制,在请求到达之前即完成部分准备工作,进一步缩减了time-to-first-token指标,提升了整体响应流畅度。
从应用层面来看,减少模型延迟还能带动用户粘性和满意度的提升。尤其是在智能助手、在线教育、内容生成等对话密集型场景中,快速响应不仅提升交互自然度,更能降低用户等待焦虑,增强交互体验的沉浸感。随着技术的进步,结合边缘计算与本地推理的混合架构趋势日益明显。这种架构能够在接近用户的节点执行部分推理任务,降低云端处理负担和网络传输时间,实现更优延迟表现。未来,融合多模态模型和多任务学习的LLM,也将面临更高的性能挑战,如何在保证计算效率的同时,满足丰富交互需求,是行业持续探索的方向。总体来看,2025年LLM延迟排行榜不仅为业界提供了量化的性能对标,还引发了对云端架构设计、模型优化策略及用户体验平衡的深入思考。
保持对新兴技术和优化方案的关注,灵活选用匹配业务场景的模型,将是驱动智能应用成功的关键。未来,随着硬件加速器的普及与算法优化的突破,云端大语言模型的响应速度有望进一步提升,推动人工智能服务迈向更广阔的应用天地。 。