近年来,随着人工智能技术的飞速发展,变换器(Transformer)模型以其卓越的性能成为自然语言处理和计算机视觉领域的主力军。尽管现有的变换器架构在诸多任务中表现优异,它们仍面临着若干限制,尤其是在扩展性及复杂推理能力方面。能源基变换器(Energy-Based Transformers,简称EBTs)作为该领域的创新突破,为解决这些挑战提供了革命性的思路和技术路径。能源基变换器不仅通过自监督学习实现了跨模态的泛化能力,还引入类似人类系统2思维的推理机制,展现出卓越的学习与“思考”能力,为人工智能的发展注入了全新动力。能源基模型的核心理念是,通过赋予输入和候选预测对一个能量值,衡量其兼容性或“合理性”,推动模型在推理过程中不断优化预测,从而实现更精准的决策过程。EBTs正是此理念在变换器架构中的创新应用。
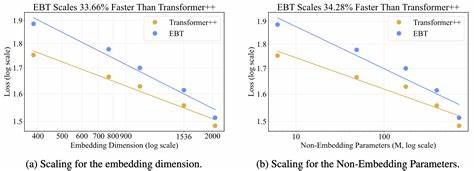
该模型将预测问题转化为能量最小化的优化过程,通过梯度下降在推理阶段反复迭代调整输出,直到达到能量收敛,从而自动判断“何时停止思考”。这种方法不仅突破了传统前馈变换器的一次性预测限制,还赋予模型类似人类反复斟酌、验证的推理能力。相较于常规的Transformer++模型,EBTs在多个扩展指标上实现了更快的扩展速度,包括数据量、批量大小、参数规模、算力消耗(FLOPs)以及模型深度。具体而言,EBTs在训练过程中展现出高达35%的加速扩展率,这意味着随着数据和计算资源的增加,EBTs能够更高效地提升性能。此外,在推理阶段,EBTs通过多步迭代的系统2思维显著提升了任务表现,相较于Transformer++,其语言模型任务的性能提高了29%。这一优势在面对复杂、远离训练分布的测试数据时表现尤为突出,表明EBTs具备更强的泛化能力和鲁棒性。
除了语言领域的应用,EBTs在视觉任务上同样表现优异。以图像去噪为例,EBTs超过了扩散变换器(Diffusion Transformers)的表现,同时将前向传播次数减少了99%,极大地提高了推理效率。这一突破不仅降低了模型的运行成本,也为实时视觉处理和资源受限环境的应用奠定了基础。EBTs的训练方式完全基于无监督学习,无需额外的验证信号或人工奖励,这使其能够从海量、多样化的数据中自主发现和验证输入与预测间的合理关系。这种通用性为跨模态、跨任务的应用提供了可能,并助力人工智能模型实现更广泛的适应性和灵活性。能源基变换器通过能量最小化实现预测的过程,本质上是对模型内部状态的连续反思,类似于人类通过反复推敲和修正来做出决策。
这种机制不仅有助于捕获更深层次的语义和结构信息,还支持模型在面对不确定和复杂输入时做出更合理的响应。此类系统2思维的涌现标志着人工智能推理能力的质的飞跃。在学术界和工业界,EBTs的出现引起了广泛关注。多个开源项目和相关论文陆续发布,促进了该领域的快速发展和应用推广。研究人员利用EBTs已在机器翻译、文本生成、图像重建等多个领域进行了实验,结果表明其能够在数据量有限的情况下实现出色的性能,同时具备更强的泛化及抗干扰能力。展望未来,能源基变换器有望成为智能系统设计的新范式,对机器学习模型的架构创新、无监督学习策略以及推理机制优化产生深远影响。
借助EBTs的高度扩展性和跨模态适应能力,人工智能将更好地模拟人类认知过程,提升语言理解、视觉感知乃至多模态融合的智能水平。总体而言,能源基变换器集成了能量模型的理论优势和变换器的结构灵活性,成功地实现了从数据学习到推理思考的无缝衔接。它不仅突破了现有模型在规模和性能上的瓶颈,更开创了将“思考”纳入机器学习推理流程的新纪元。随着研究的不断深入和技术的日益成熟,能源基变换器将在人工智能发展史上留下浓墨重彩的一笔,引领未来更加智能和自主的机器系统迈向更加广阔的天地。