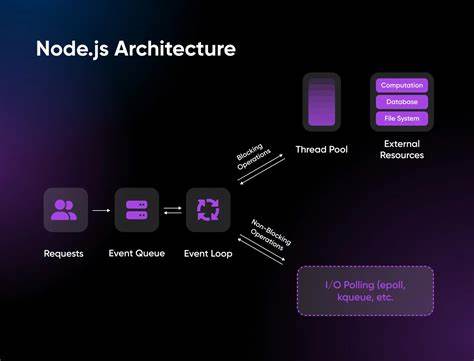
随着人工智能、机器学习和大数据处理的不断发展,计算性能的瓶颈日益凸显。传统CPU在执行大规模并行计算任务时往往力不从心,而图形处理单元(GPU)以其卓越的并行处理能力,成为提升计算效率的关键利器。然而,尽管GPU加速已经在Python等语言中广泛应用,JavaScript领域尤其是Node.js在这方面的探索却相对有限。如今,GPU原生计算在Node.js中实现的突破,正标志着一个全新技术时代的来临,极大地丰富了JavaScript的应用场景和性能表现。Node.js实现原生GPU加速的基础在于开发了一款全新的原生插件,使得JavaScript代码可以直接调用GPU资源,而无需依赖Python等外部库。这一创新不仅极大缩短了计算流程,更重要的是简化了开发者的编程体验,从而实现前后端语言的统一,提升项目开发效率和维护性。
这款原生GPU插件具备跨平台的兼容性,可在Windows、Linux和macOS等主流系统上运行,支持包括Vulkan、DirectX、Metal、OpenGL和WebGL等多种GPU底层渲染后端,满足各种硬件环境的需求。它支持异步操作与async/await语法,使得GPU计算任务能够并行高效地执行,同时保持JavaScript代码的简洁与可读性。该项目的创始人通过持续的低层优化和引擎研发,成功克服了深度性能调优的复杂挑战,实现了与主流机器学习框架相媲美的计算速度。具体来看,在神经网络训练方面,GPU原生插件已经实现了自动微分(Autograd)、密集层(Dense Layer)、优化器(Optimizer)等关键功能,完成了从前向传播到反向传播及优化步骤的完整训练流程。这意味着开发者能够在Node.js环境中运用GPU加速进行深度学习模型的训练与推理,而无需借助Python生态系统,极大拓展了JavaScript在AI领域的应用空间。Tensor操作和各种神经网络激活函数也得到了完备支持,涵盖了elu、relu、sigmoid、softmax等多种常用函数,配合丰富的张量操作接口如reshape、concat、slice、stack等,使得基础的数学运算与复杂数据处理皆能高效执行。
此外,项目不仅关注功能完备,更注重性能表现。创始人重点优化了矩阵乘法和核心引擎计算,针对中端GPU设备进行了广泛测试,在保证兼容性的同时达到了显著的性能提升。未来计划包括与PyTorch兼容的API层开发,方便开发者无缝迁移现有代码,进一步推动Node.js GPU加速生态的发展。目前尽管项目因资源调配原因暂时搁置,但这份里程碑式的成果已为社区奠定坚实基础。随着硬件性能的不断提升及生态完善,GPU原生计算将在游戏开发、机器学习、图像处理等领域发挥更大作用。Node.js开发者们只需通过简单的接口调用,即可获得GPU带来的高性能计算能力,实现复杂任务的加速,推动技术创新。
简而言之,Node.js原生GPU计算的出现打破了以往对外部依赖的限制,让前后端开发语言真正实现高度整合。此举不仅提升了JavaScript的技术层次,也扩展了其应用边界,为未来高性能计算和AI落地提供了有力支撑。尽管挑战仍存,但随着开发者社区的积极响应与持续投入,GPU加速将成为Node.js生态的重要组成部分,激发无数创新可能。展望未来,本地GPU计算为开发者带来前所未有的灵活性与效率,使复杂任务的实现更加简洁优雅。随着技术的成熟和应用的普及,Node.js有望在高性能计算领域占据一席之地,推动数字经济和智能时代的蓬勃发展。 。