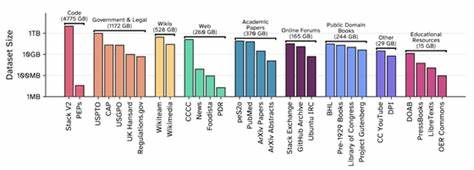
随着人工智能技术的快速发展,尤其是大型语言模型(LLM)的兴起,训练数据的重要性愈发凸显。数据的规模、质量及其合法合规性不仅直接影响模型的性能,还关系到研究的透明度和社会责任。而The Common Pile v0.1作为一款全新的大型开放许可文本数据集,其问世为学界和业界带来了革新契机,也为AI的发展注入了新的活力。该数据集由知名开放科学社区EleutherAI领衔,与多家顶尖学术机构和研究组织共同打造,旨在建立一个庞大且完全开放的训练语料库,助力推动更加负责任和透明的人工智能研究。The Common Pile v0.1包含了高达8TB的公开领域和符合严格开放许可标准的文本数据,汇集了约30个不同来源的优质数据集合。这一项目的初衷源于EleutherAI在五年前推出的The Pile数据集,其以800GB多样化文本首次实现了大规模GPT-2令牌规模的训练,为开源语言模型领域奠定了里程碑式的基础。
如今,随着模型规模和复杂度的不断提升,对训练数据的需求也相应扩大,而The Common Pile v0.1正是对此需求的有力回应。新版本的数据集不仅容量较前作大幅增加十倍,而且更强调了数据的合法性与开放性。EleutherAI团队联合多方专家对数据许可证进行严谨评估,采纳了蓝橡树理事会(Blue Oak Council)和开放知识基金会(Open Knowledge Foundation)关于开放许可的定义,确保数据允许任何人自由使用、修改和再分发,真正实现了开源精神。值得注意的是,团队也特别关注公共领域作品的识别和收录,这类作品因版权期限终止或各种法定原因已无需许可即可使用,但由于司法管辖区和标注方式差异,确认其身份十分复杂。他们通过手动验证和元数据分析最大限度地保证了数据集的可靠性和合规度。The Common Pile v0.1的构建过程同样体现了开放协作的典范,EleutherAI联合了包括多伦多大学、向量研究所、Hugging Face、阿伦研究所、康奈尔大学、麻省理工学院、卡内基梅隆大学等多座学术和研究重镇,还与图书馆、档案馆以及文化遗产机构建立合作,共同推进高质量开源数据的采集与整合。
项目中还开发了多种数据提取、质量检测和许可证识别工具,并计划持续开放这些资源,促进整个社区的数据基础设施建设。此外,团队利用开源OCR和语音转录技术如Docling和Whisper来提升文本和音频数据质量,希望未来能进一步扩展多模态数据的开放可用性。这不仅增强了数据的丰富性,也使得更多公共领域作品可以以更高的质量被纳入训练语料,惠及更多研究者和开发者。针对广泛存在的对开放许可数据训练模型性能质疑,EleutherAI通过实际训练展示了基于The Common Pile v0.1的7B参数模型(Comma v0.1-1T和Comma v0.1-2T)在标杆任务中的竞争力表现。实验结果表明,这些通过严格筛选的开放许可数据训练的模型性能不逊于许多未经许可数据训练的模型,且在与其他许可数据集及未许可数据集的对比中,表现也非常优异。这有效打消了业界关于开放数据无法驱动高质量模型的疑虑,说明随着更加丰富数据的开放获取,未来的AI模型有望以更加规范和负责任的方式持续提升。
The Common Pile v0.1的发布还响应了近年来因版权和隐私诉讼而导致的数据透明度下降的问题。它不仅为研究人员和开发者提供了一个公认的、合法的训练语料库,也为模型评估中的数据泄漏风险和偏见分析提供了可靠的基线,推动了AI领域的科学性和可验证性。其实践充分体现了开放科学倡议的价值,强调公众有权了解和监督影响其生活的技术背后的数据与算法机制,从而促进AI使用的公平性和责任感。未来,EleutherAI及其合作伙伴计划基于The Common Pile系列继续扩大开放数据的规模和种类,强化对低质量数据的过滤与标注,探索后训练阶段的开放数据利用,逐步建立一个涵盖多语言、多模态,且法律明确的AI训练数据生态。与此同时,期待更多图书馆、博物馆和文化机构加入,共同推动公共文化资源数字化和法律透明化,破解长久以来的版权迷雾,真正实现知识共享与AI进步的双赢。综上所述,The Common Pile v0.1不仅是一个海量且高质量的大型语言模型训练数据集,更是一项推动开放数据治理、提升AI研究科学性和道德标准的重要里程碑。
通过开放许可文本的积累与共享,它为全球研究者解锁了更多实验空间,保证了技术进步的合法合规与社会责任,为AI的未来发展树立了新的标杆。在数据可获取性日益成为核心竞争力的时代,The Common Pile v0.1正作为一个开源界的典范引领行业前进,为构建更加公平、透明和高效的人工智能世界贡献着力量。未来,期待更多相关项目和社区能效仿此模式,共同促进开放、合作与创新,推动人工智能造福更广泛的人群。