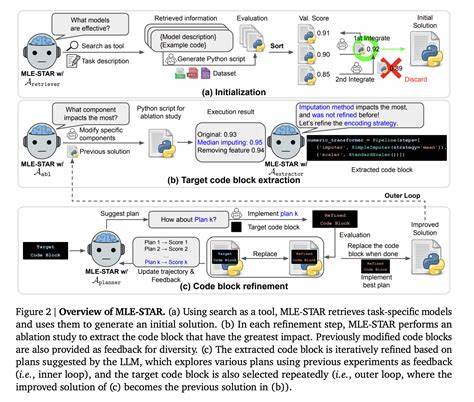
随着人工智能技术的飞速发展,机器学习(ML)已成为推动各行各业创新的关键技术。然而,机器学习模型的设计与优化仍然是一项高度复杂且耗时的工作,尤其需要工程师在数据处理、特征工程、模型选择和调优之间进行反复实验。为了解决这一难题,研究者开始探索通过大型语言模型(LLM)作为机器学习工程代理,以实现对机器学习任务的自动化管理和优化。MLE-STAR正是在这一背景下应运而生的前沿技术,展现出令人瞩目的应用潜力和效果。 MLE-STAR是一款先进的机器学习工程代理,能够自动完成多模态数据的机器学习任务,且在多个知名比赛平台取得了优异成绩。其核心创新在于首先利用网络搜索功能,实时检索当前最有效、最新颖的模型与策略,从而为机器学习任务搭建坚实的起点。
随后,MLE-STAR通过编程代码块的精准定位和迭代精炼,针对不同机器学习流水线组件展开深度优化。这一方法不仅克服了传统代理容易陷入固定思维模式的弊端,还实现了模型性能的持续提升。 与传统机器学习代理大多依赖预训练的语言模型知识不同,MLE-STAR能够主动搜寻最新科研成果及相关技术文档,有效避免了对已有库和方法的过度依赖,挖掘更具针对性的解决方案。其独特的代码块筛选机制通过消融实验找出对表现影响最大的流水线环节,进而集中资源进行反复调整和验证。这种精准定位和迭代改进的方法,使得在特征工程、模型集成等关键环节中,可以深入探索多种创新策略,从而找到最优解。 此外,MLE-STAR首创了一种动态集成方案生成机制,能够智能融合多个备选模型,迭代优化最终集成策略,超越了以往基于简单投票或加权的集成方法。
这种灵活的模型合成策略大大提升了整体预测的鲁棒性和准确度,体现了其在复杂数据环境下的强大适应能力。与此同时,为避免因代码自动生成而导致的错误和偏差,MLE-STAR还配备了调试代理、数据泄漏检查器和数据使用检查器,保障代码执行的正确性和数据利用的全面性。 MLE-STAR的卓越表现已在多个由谷歌推出的机器学习竞赛集成平台MLE-Bench-Lite得到充分验证。它在众多挑战中斩获63%的奖牌,其中超过三分之一为金牌,显著领先于同期其他自动化代理。这不仅反映了其强大的技术实力,更展示出该系统在现实场景中推动自动机器学习解决方案向前发展的巨大潜力。 值得一提的是,MLE-STAR在模型选择上的多样性和前瞻性也为其优势贡献良多。
它不仅优先采用效率更高且更具竞争力的现代深度学习架构,如EfficientNet和视觉变换器(ViT),还支持人类专家在框架内灵活介入,快速引入最新研究成果,实现人机协同创新。此举强化了系统的开放性和扩展性,使得MLE-STAR能够持续拥抱学科前沿,保持技术领先地位。 在实际应用层面,MLE-STAR的自动化流程极大地降低了机器学习项目的入门门槛,使得中小型企业乃至非专业人士也能借助其技术力量开展高效的数据驱动创新。通过自动寻找最适合任务的模型,精准优化关键流程步骤,并动态调整集成方案,MLE-STAR为多个行业的决策制定、产品研发提供了强有力的技术支持。 谷歌团队为方便社区共享和创新合作,已将MLE-STAR的代码库开源,并基于代理开发套件(Agent Development Kit,ADK)进行建构。这意味着研究人员和开发者可以在此基础上进一步完善和定制代理功能,推动自动机器学习技术向更广泛的领域落地。
总之,MLE-STAR代表了机器学习工程自动化的新时代,通过结合互联网实时信息检索、对代码模块的深度精炼及智能模型集成,不仅有效提升了机器学习任务的执行效率和模型表现,还为整个AI生态带来了更加灵活且强大的智能代理范例。未来,随着机器学习领域的不断进步和创新,MLE-STAR有望持续提升自身解决复杂问题的能力,成为推动AI赋能各行业的重要引擎。