随着人工智能技术的飞速发展,越来越多的AI模型涌现市场,如何科学评估和选择合适的模型成为业内和用户关注的焦点。面对琳琅满目的模型类别和版本,单纯依靠主观体验难以准确判断模型的性能优劣,因此依托各类有代表性的性能基准成为主流手段。本文将深入探讨目前广泛使用的评测基准及其在实际中应用的价值,帮助读者更好地理解和甄别不同AI模型的适用性和优缺点。 首先,编码能力是很多现阶段人工智能模型的重要应用方向,特别是开发者和企业依赖AI辅助编程时,对代码生成的准确性和多样性要求较高。因此,许多评测者倾向使用Aider的Polyglot基准测试平台。该平台不仅涵盖了多语言代码的性能表现,还通过真实编码任务评测模型的综合能力,为选择擅长代码处理的模型提供直观数据。
Polyglot的优势在于它能反映模型在多语言、多环境编程中的实际表现,特别适合用于比较各种AI编程助手的实用性。 除了针对特定能力的细分基准,模型的普及率和使用频率也能间接反映其实用价值。OpenRouter平台提供的模型使用排名被不少行业人士视为重要参考指标。这个排行榜根据模型在实际环境中的调用频率进行排序,使用人数越多,模型的实用性和用户认可度相对较高。虽然人气不能完全等同于性能,但在面对选择困难时,流行程度可以作为一种参考,尤其适合刚入门或需求广泛的用户选型参考。 从数据可视化的维度,LLM-Stats提供了丰富多样的图表和数据集,涵盖许多细致的性能指标和模型间对比。
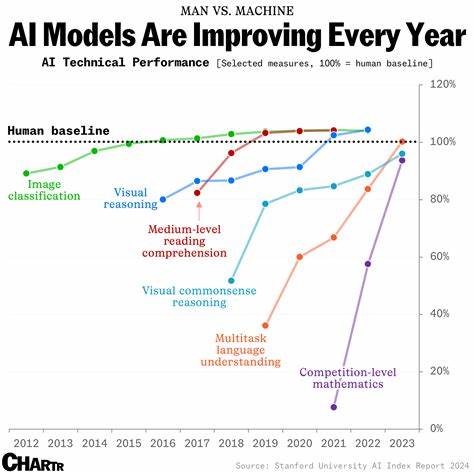
它不仅展示了模型的基本指标如推理速度、准确率,还包括复杂任务的表现趋势,帮助评测人员从宏观和微观两个层面衡量模型优势。对于需要综合考量多个性能维度的专业应用,LLM-Stats的图表分析为决策提供了数据支持,极大地增强了选型的科学性。 然而,尽管有众多标准化基准的存在,不同用户在选择模型时依然持有不同的观点。一些专业人士建议直接选择市场上的主流模型,如OpenAI的几款代表产品,依靠它们在速度、功能多样性和稳定性上的差异做出最终取舍。这样的方法简化了决策流程,降低了测试成本,特别适合工作节奏快且需求多样的用户。他们认为大品牌的模型经过大量用户验证,体验差异可能没有想象中大,选择知名品牌能够保证基本的性能和持续的更新支持。
相反,也有用户认为目前主流前沿模型数量有限,完全可以逐一深入体验,从实际使用中获得更贴合需求的认知。对于高级用户和机构来说,模型的微小差别往往影响较大,因此他们更注重亲自验证各种任务下的表现,而非单纯依赖公开基准分数。这样的“实战测试”更多依赖经验和场景匹配度,能够为具体业务找出最适合的模型。 总体来看,评估AI模型需要结合多方面维度。标准化的性能基准为评测提供了科学依据,而使用频率和用户口碑则补充了实际体验层面的评价。不同需求用户应根据自身应用场景合理选择测试重点,例如编码领域优先参考Polyglot,数据全面性依赖LLM-Stats,流行模型选型则关注OpenRouter排名。
此外,进行实际操作体验和跨模型对比也十分必要,以确保模型在现实任务中表现稳定且高效。 随着AI系统不断迭代更新,评测基准自身也在持续演进。例如,未来更多会引入多模态数据测试、复杂推理能力检验以及模型安全性评估等指标。此外,以任务为中心、用户反馈驱动的评测体系将逐渐成为主流,更加贴合真实应用需求。与此同时,评测社区的开放性和透明度提升也将促进AI模型生态的健康发展,保障用户权益。 总之,科学的评估方法不仅能帮助使用者准确了解模型能力,更助力开发者改进算法,提高产品竞争力。
建议相关从业人员持续关注各类榜单和测试平台,结合自身场景进行多维度评测,理性选择最适合的AI模型。只有这样,才能最大化人工智能技术带来的价值,让AI真正服务于生产力提升和社会发展需求。