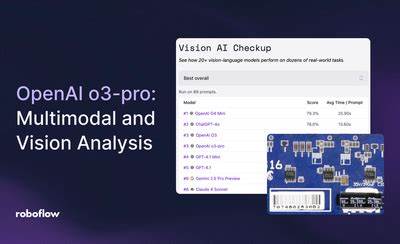
随着人工智能技术的不断进步,多模态模型成为推动智能理解能力跨越式发展的关键。2025年6月10日,OpenAI推出了其最新的多模态推理模型o3-pro,凭借其在文本与图像处理上的卓越能力,迅速引起行业内外的广泛关注。o3-pro集成了强大的视觉和语言理解功能,具备高达20万标记上下文窗口和截止于2024年6月1日的知识库,其卓越的推理能力在当今模型中名列前茅。作为多模态技术的新突破,o3-pro不仅支持多重输入形式,还在多个实际应用测试中展现了出色的表现,显示出它在工业和科研领域的广泛潜力。 o3-pro的强项主要体现在光学字符识别(OCR)、视觉问答(VQA)以及缺陷识别等任务上。具体来看,o3-pro能够准确读取图像中的序列号和条形码ID,如成功识别复杂电路板上的序列号“T074802630B2”,展现出了极高的精准度。
在视觉问答场景下,模型能合理回答关于图像内容的细节问题,例如有效判断货物包装数量,提供符合实际的数值答案,这种能力在物流及仓储管理方面意义重大。此外,o3-pro在缺陷检测中的表现也较为出色,能识别金属表面的划痕并判定标签区域的内容,精准识别“eat well”标签说明了其对细节的敏锐捕捉力。 在检测物品缺失情况的测试中,o3-pro同样表现出色,能够判断图像中缺少了多少个部件,在生产质量监控中提供有力支持。这种视觉推理能力体现了模型对空间和物体关系的深刻理解,为智能化制造和质检环节增添了强大技术保障。值得一提的是,该模型不仅限于静态图像的分析,还能处理复杂场景中的物体背景关系,进一步拓展了多模态AI的应用边界。 然而,尽管o3-pro在多方面表现优异,但它仍存在明显的局限。
令研究者和用户关注的是,该模型在物体计数和尺寸测量方面的表现有所欠缺。测试显示,在计数瓶子数量时,模型回答26而非正确的27个,显示出计数准确性有待提升。此类问题并非o3-pro独有,而是当前多模态模型普遍挑战之一,即如何精准处理相互遮挡、多尺度或密集排列的目标物体。与此同时,针对长度和宽度的测量,模型预测结果常偏离真实数值,这在工业检测和质量评估中限制了其实用性。 尺寸测量难题源于视觉信息与真实物理尺度的映射复杂度,以及图片中尺子、标尺等参考物的识别和解析难度。特别是在不同角度、光照和遮挡条件下,模型的误差积累较大。
调查显示,只有少数模型能在测量任务中取得良好成绩,表明该领域还需持续突破。从长远来看,结合3D感知或更多传感器数据,多模态模型有机会实现更精准的物体尺寸认知。 目前,OpenAI o3-pro已开放多平台使用,包括ChatGPT网页版、在线Playground以及API接口。开发者通过v1/responses API即可调用模型,实现文本与图像混合输入的智能交互。Python用户则可通过client.responses.create API完成请求发送。多样的接入方式满足不同需求的研究人员和企业用户,使其快速融入各类智能应用场景,如智能质检、仓储自动化和内容监控。
值得关注的是,o3-pro属于OpenAI“o”系列推理模型的一员,强调思考时间与精确回答的平衡,为复杂问题带来更深层次的思考能力。这种设计理念使其在解决图像与文字结合的复合任务时更加得心应手,进一步推动了多模态AI的智能化水平。与此同时,在实际应用中,用户也需根据具体需求权衡模型速度与准确率,合理调配资源。 展望未来,o3-pro的发布标志着多模态AI技术的又一里程碑。随着更多细节优化和训练数据的积累,其在图像识别、视觉推理以及跨模态理解方面的能力将不断增强。结合其他先进模型如Gemini与Claude系列,整个计算机视觉生态系统正朝着更精准、更全面的智能分析迈进。
多模态模型将逐步融入医疗诊断、工业制造、自动驾驶等多个高价值领域,推动人工智能在现实世界的深度落地。 总结来看,OpenAI o3-pro凭借其卓越的多模态处理能力和丰富的应用测试结果,确立了其在当下AI视觉分析领域中的领先地位。尽管存在计数和测量方面的不足,但其闪耀的OCR、视觉问答及缺陷检测能力表现出强大的实用价值。未来,随着技术的不断进化,o3-pro及其后续版本有望进一步提升智能视觉的精准度和广泛适应性,开启多模态AI全新的发展篇章。企业与开发者可积极探索其应用潜力,推动数字化转型与智能升级,抢占新时代人工智能的制高点。