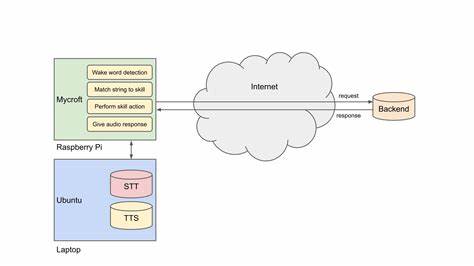
随着人工智能技术的迅猛发展,语音识别(STT)和语音合成(TTS)技术已成为现代人机交互的重要桥梁。无论是智能助手、客服系统,还是多媒体内容制作,精准且高效的语音处理能力都有着不可替代的价值。在众多技术方案中,Speaches作为一款基于faster-whisper打造的本地API服务器,脱颖而出,成为开发者实现高质量语音服务的利器。 Speaches起初名为faster-whisper-server,随着项目逐步拓展功能,现已发展成支持多种语音模型的综合型本地API服务器。它采用与OpenAI API兼容的设计理念,极大地方便了开发者利用已有工具和SDK进行集成,无需重新学习新的接口规范,快速实现语音转录、语音合成甚至多语种翻译等多元功能。 核心技术方面,Speaches的语音识别部分基于faster-whisper,利用深度学习优化的模型为语音转文本提供高效且精准的支持。
相比传统Whisper模型,faster-whisper不仅提升了推理速度,同时降低了资源占用,使得在有限的硬件环境中也能运行流畅。与此同时,Speaches在文本转语音方面集成了piper和kokoro模型,其中kokoro凭借自然度与清晰度在多个TTS竞赛中排名第一,协助用户打造听感舒适、语调自然的语音内容。 Speaches支持的功能极为丰富,能满足多样化的应用场景。它不仅能实现按需模型加载和卸载,智能管理系统资源,避免不必要的运算浪费,同时支持实时流式转录,用户可在语音尚未完整输入时,就获得逐步返回的转录文本,极大提升交互效率和用户体验。这对于会议记录、在线课堂、实时字幕等场景尤为关键。 值得关注的是,Speaches允许通过普通的HTTP请求指定所需模型,无论是采用CPU还是GPU运算资源,系统均能智能调度,确保运行稳定与高性能。
此设计增强了服务器的灵活性与扩展性,用户可以根据任务复杂度与硬件配置自由选择适配方案,从而实现最佳的资源利用率。 此外,Speaches支持音频输入后直接生成情绪分析结果,这一创新功能为语音内容的情感洞察提供了新的维度。通过结合语音转文本和附加的情感识别模块,企业可更精准地把握用户情绪,优化客户服务或者进行市场分析。 安装与部署方面,Speaches提供了Docker与Docker Compose的官方支持,使得服务部署变得异常便捷和一致。无论是在本地服务器、私有云还是边缘计算设备,开发者均可快速搭建完整的TTS/STT服务体系,节省了环境配置与依赖管理的繁琐流程。 Speaches项目的开源性质也促使社区贡献层出不穷,用户不仅能自由定制与扩展功能,还能通过GitHub平台及时反馈问题、提交改进建议,使得项目持续迭代完善,形成了一个活跃的技术生态圈。
在现代应用开发中,兼容性是实现高效集成的关键。Speaches兼容OpenAI的API标准,意味着在现有支持OpenAI接口的软件环境中,开发者无需修改代码即可快速切换到Speaches,实现本地部署语音服务,有效避免数据隐私问题,以及网络延迟带来的性能瓶颈。 从用户体验角度看,Speaches的实时API设计极大提升了交互的连贯性和响应速度。音频数据上传后,转录结果通过SSE(服务器推送事件)实时返回,开发者可即时更新最终用户界面,给用户带来几乎无感延迟的流畅体验。这对于需要即时语音反馈的智能设备或者远程协作软件尤为重要。 结合kokoro和piper两款先进的TTS模型,Speaches不仅能输出高质量的合成语音,还支持多种语言和音色选择,满足个性化和定制化需求。
无论是制作有声书、播客,还是搭建语音导航系统,Speaches都能提供丰富的语音表达能力。 面对未来的语音技术应用,Speaches体现了强大的可适应性和前瞻性。其动态模型加载机制不仅提升了资源利用率,也为多模型共存提供了可能性,使得在同一服务中灵活切换不同语种、不同任务的模型成为现实。同时,其开放的架构为深度学习模型的持续集成和更新提供了便利条件,确保技术始终保持领先。 综合来看,Speaches作为一款基于faster-whisper的本地API服务器,融合了尖端的STT和TTS技术,兼容开放的API标准,支持灵活配置及部署,为语音交互应用的开发和落地提供了强有力的技术支撑。无论是个人开发者、小型企业,还是大型技术公司,都能受益于Speaches带来的高效、实时、定制化的语音服务解决方案。
未来,随着模型性能的不断优化和生态系统的日渐完善,Speaches有望成为本地语音应用的核心平台,推动语音技术从实验室走向更广泛的实际应用场景,让人与机器之间的沟通更自然、更智能、更便捷。









