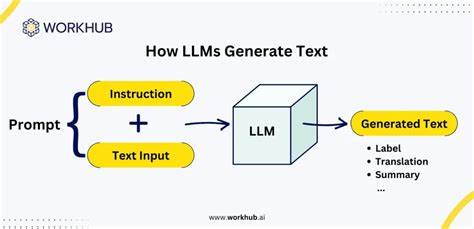
随着人工智能技术的迅速发展,大型语言模型(Large Language Models,简称LLMs)已经成为自然语言处理领域的重要突破。它们凭借强大的语言理解和生成能力,推动了智能写作、自动文本摘要、机器翻译等多项应用,实现了前所未有的高效性和智能化。为了更好地理解LLMs如何生成文本,本文将从基础理论出发,结合实际案例,逐步揭示其生成文本的全过程。 首先需要明确,LLMs的核心是一种基于深度学习的神经网络模型,通常采用变换器(Transformer)架构。该架构具有强大的上下文理解能力,能够捕捉词语之间的复杂关联和语义信息。在训练阶段,模型以海量文本数据为基础进行"预训练",通过自回归或自编码方式学习语言的统计规律与语义结构。
文本生成实际上是模型基于给定的输入或提示(Prompt),预测下一个最可能出现的词语或字符,并逐步扩展生成完整文本的过程。模型不仅仅是机械地复制训练数据,而是根据学到的语言模式进行合理推断,产出流畅且内容相关的文本。在生成过程中,可以通过调整温度参数来控制文本的多样性,实现内容的创新或保守。 在实际应用中,用户通过向LLMs输入简短的文本提示,模型便会自动延展生成相应的段落或文章。例如,在新闻写作中,编辑可以提供关键词或标题,系统随后自动补充内容,提高写作效率和创新力度。此外,客服机器人利用LLMs进行文本生成,实现自然、流畅的对话交互,极大地提升了用户体验。
随着技术的深入,文本生成的质量也在不断提升。大型语言模型不但能够理解复杂的上下文关系,还能够在生成过程中考虑逻辑一致性和主题连贯性,避免出现无意义或重复的内容。同时,模型在生成的文本中能够体现多样的风格、语气和表达方式,满足不同领域的需求。 不过,LLMs文本生成也面临一些挑战。首先是数据隐私和内容安全问题,模型生成的内容可能存在偏见,甚至误导信息。因此,研究人员不断开发更加安全和可控的模型版本,确保生成结果符合伦理和规范。
其次,尽管模型规模庞大,但依然存在理解深层语义和常识推理的不足,需要结合更多外部知识和多模态信息提升智能水平。 未来,随着算力提升和算法优化,LLMs在文本生成领域将展现更强的创造力和适应能力。结合图像、音频等多媒体信息,模型将能实现更加丰富和多样的内容生产,不仅仅局限于文字。同时,个性化定制的模型服务将使用户能够根据自身需求调整生成风格和内容,真正实现智能化内容创作的普及。 总之,大型语言模型的文本生成技术正在重塑人们与文字互动的方式。了解其背后的原理和特点,有助于更有效地利用这一强大工具,提升工作和生活的智能化水平。
随着技术不断成熟,相信未来文本生成将更加精准、丰富与创新,成为数字时代的重要引擎。 。