在现代软件系统架构中,微服务架构因其灵活性与可扩展性备受青睐。然而,随着服务数量的增加,如何在多个独立服务之间保证数据一致性成为亟待解决的难题。传统的数据库事务通常依赖ACID属性,尤其适用于单一数据库环境,但当系统数据分散在不同服务及数据库中时,这些事务特性难以保持。Saga分布式事务模式正是在这一背景下应运而生,旨在为分布式环境下的数据一致性提供一种有效的解决方案。Saga模式的核心思想是将单一长事务拆分为一系列本地事务,每个事务都在各自的服务范围内完成并提交,依靠事件或消息驱动串联各个局部事务。若执行过程中某个步骤失败,系统则通过补偿事务逐步撤销之前的操作,从而防止数据不一致问题。
设计Saga模式需深刻理解事务的基本概念。事务是完成特定业务需求的一组操作集合,伴随着状态的变化。而事件则代表了实体状态的改变,命令则是触发这些事件的操作请求。传统事务遵循原子性、一致性、隔离性和持久性等ACID原则,但这些特性难以跨多服务数据库实现。微服务架构强调服务数据独立,每个服务拥有专属数据库,不同服务可选用最合适的数据库技术和模式,同时实现服务独立扩展及故障隔离。然而,由于缺乏全局事务支持,跨服务的数据同步与一致性面临挑战。
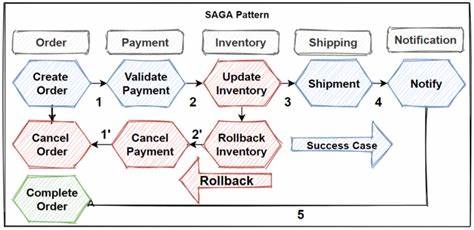
基于此,Saga通过将业务操作分解为顺序执行的本地事务来管理分布式状态变化。每个本地事务先完成自身数据库更新,随后通过事件通知触发下一个事务的执行。如遇失败,分布式补偿机制将启动,依次逆转先前成功的操作。Saga支持的交易类型包括可补偿事务、支点事务和可重试事务。可补偿事务允许通过逆向操作实现撤销;支点事务是"不可回头"的节点,之后的操作必须完成以保持数据最终一致;而可重试事务则使系统具备失败恢复能力,确保最终可达一致状态。Saga的实现方式主要包括编排(Orchestration)和编排(Choreography)两大类。
编排模式依赖中央协调者,负责控制整个事务流程,并根据参与服务状态指挥具体事务执行与补偿操作。此模式适用于复杂流程,便于管理与监控,但引入单点协调风险。编舞模式则由各服务独立发布并响应事件,没有中心控制者,事务通过事件链自然推进,避免单点故障,但实现更为复杂,容易产生命令循环,且对交易流程的追踪较困难。Saga模式在设计和实施过程中面临诸多挑战。首先,理念转变明显,开发者需从整体流程协调角度思考事务执行,而非依赖传统单体数据库事务保障。其次,Saga事务的调试与日志跟踪较为复杂,特别是服务参与数目众多时。
此外,由于各服务提交已发生,标准回滚操作不可行,补偿事务必须设计得当且能够可靠执行。系统还需确保操作的幂等性,即多次重复执行不产生不一致影响,这对于处理瞬时失败至关重要。监控与追踪Saga执行状态变得尤为重要,通过监测工具实时掌控事务流转,有助于及时发现异常和数据不一致风险。Saga的应用场景极具代表性,尤其在电商、金融结算、票务预定等业务流程复杂且涉及多系统协同的领域表现突出。其分布式数据一致性管理方式既避免了两阶段提交协议(2PC)带来的阻塞和性能瓶颈,也提升了系统的容错与扩展能力。不过,Saga并非适用于所有场景。
对于需要极强数据一致性保障以及无法设计补偿操作的业务,传统强事务或分布式事务机制仍具有不可替代优势;而Saga模式不适合存在循环依赖的事务流程,会导致死锁或事务失败。此外,Saga模式容易产生某些数据异常,如丢失更新、脏读和非重复读等问题。针对这些异常,开发者可以采用语义锁、幂等设计、脏数据隔离、版本控制等策略来缓解风险。同时,根据业务风险选择合适的并发控制手段,将Saga与分布式事务机制相结合,也是不少企业实践中的创新方案。除了核心的Saga模式,相关分布式模式如补偿事务(Compensating Transaction)、重试(Retry)、断路器(Circuit Breaker)以及健康端点监控(Health Endpoint Monitoring)等,共同构成了现代云原生架构数据一致性保障的基础。它们在处理业务异常、保障系统稳定方面发挥着互补作用,提升整体服务质量。
总之,Saga分布式事务模式作为微服务架构下数据一致性的利器,为跨服务跨数据库的复杂业务提供了切实可行的解决路径。通过合理拆分事务、灵活运用补偿机制及事件驅动协调,Saga有效避免了传统分布式事务的性能瓶颈与管理复杂度,助力企业构建高弹性、高可用且一致性保障的现代应用系统。未来,随着微服务与事件驱动架构的发展,Saga模式仍将持续演进,与云计算、大数据和人工智能等技术深度融合,推动分布式系统一致性解决方案迈向新的高度。 。