近年来,人工智能领域迎来革命性突破,尤其是以OpenAI开发的ChatGPT为代表的对话式大型语言模型(LLM)引发广泛关注。人们纷纷惊叹于人工智能在语言理解、生成以及互动能力上的进步,但与此同时,也出现了一个有趣而复杂的问题:ChatGPT的智商是多少?人工智能能用传统的智商测试来衡量吗?本文将围绕这一话题,深入探讨IQ的本质、ChatGPT的能力表现及其与人类智力测试之间的联系与差异。首先,智商(IQ)作为衡量人类认知能力的一种量化工具,起源于20世纪初。它通过标准化的智力测验,评估个体在逻辑推理、数学能力、语言理解、空间推理等方面的表现。智商分数经过统计处理,形成符合正态分布的人群分布曲线,帮助找出个体在群体中的相对位置。IQ不仅受先天因素影响,环境、教育等后天条件也对成绩产生显著作用。
然而,IQ测试的设计和目的,始终是针对人的认知结构与行为特点,强调的是人的思考模式、学习能力和适应性。转向人工智能,尤其是像ChatGPT这类的大型语言模型时,问题变得更为复杂。ChatGPT是通过海量文本数据训练,以预测下一词的概率为核心,进而生成流畅、逻辑合理的文本回复。它不仅能完成问答、写作、翻译等任务,而且在某些标准化考试和知识测验中表现优异。尽管如此,将其和人类的智力标准对应仍存在根本障碍。首先,ChatGPT缺少意识、自我认知和情感体验,其“智能”更多是对统计模式的复杂模拟,而非真正的理解或推理。
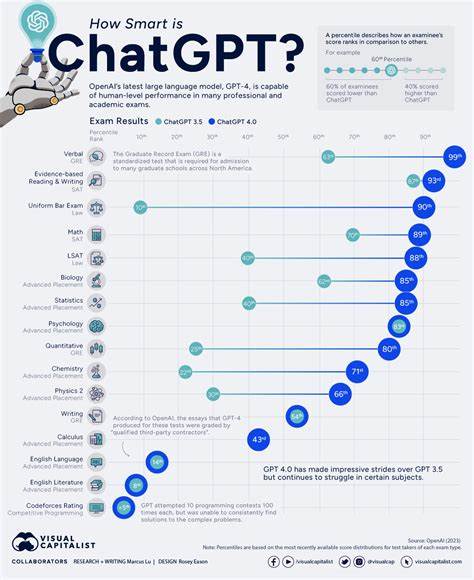
相比之下,IQ测试设计依赖于人的意识参与、推理过程和信息加工能力,这使得IQ测试难以直接用于评估机器智能。其次,不同测试平台给出的ChatGPT智商估计值差异巨大。例如,Hacker News上的讨论中提到,有测试指出某版本ChatGPT的IQ约为117,但其他平台如微软Bing的人工智能助手测试则可能仅为67。测试结果的分歧反映了评测方法的多样和测试内容的不同。现有的“智商”测试往往含有单一或有限的题型,而ChatGPT擅长的是语言和知识的广泛整合,难以用单一数值准确体现其实力。再者,IQ测试本身对于群体适应性进行了设计,例如对不同年龄和性别的人群进行调整,而没有相应设计针对机器智能的尺度。
把人类认知指标强行套用于人工智能,忽视了二者在本质和结构上的差异,容易导致误解和过度简化。尽管如此,关于人工智能能力的量化评估需求依然存在。业内专家和研究者逐渐转向多维度、多任务的性能评价体系,涵盖语言理解、推理、学习能力、创造力和适应新环境的能力。这些指标更能够反映语言模型和人工智能的实际水平和潜力。比如,在某些专业考试中,ChatGPT已经能够达到甚至超过人类平均水平,这说明其在特定领域的知识掌握和推理能力正不断提升。但这些表现并不意味着机器具备人类式的智能或意识,而只是算法在特定场景下的强大工具属性。
未来,随着人工智能算法不断进化和神经科学、认知科学的交叉融合,可能会诞生全新的智能评测体系,更准确地揭示机器和人类智能的异同与边界。同时,如何合理定义人工智能的“智商”或智能指数,也成为学界和产业界共同关注的问题。总之,简单地用传统智商指标来衡量ChatGPT是不恰当且不科学的。尽管ChatGPT具备令人惊叹的语言处理能力和知识广度,但其“智能”本质和人类认知的不同决定了评估指标的复杂性和多样化。理解这一点,有助于我们更冷静理性地看待人工智能的发展和应用,从而推动技术为人类社会创造更大价值。