随着人工智能技术的飞速发展,大型语言模型(LLM)成为了人工智能领域的核心驱动力。然而,这类模型的运行机制长期以来一直是一个谜,令学术界和业界对其原理知之甚少。近日,知名AI公司Anthropic发布了具有里程碑意义的研究成果,首次能够实时追踪大型语言模型内部的决策过程,带来对这项神秘技术前所未有的洞察。Anthropic团队利用一种被称为“电路追踪”的创新技术,像用显微镜一样观察大型语言模型Claude 3.5 Haiku在执行任务时内部各组件的活动,最终揭示了这些模型远比预想中更为复杂和奇特的运行原理。Anthropic的研究负责人Joshua Batson表示,团队在分析模型执行日常任务的过程中发现了不少令人惊讶的反直觉行为。例如,在完成一句话和解决小学数学问题时,模型表现出的运算步骤和决策过程并非直接套用训练数据中的范例,而是形成了自己独特的策略,这些策略不仅非人类直觉所设计,甚至与模型自己给出的答案解释大相径庭。
传统观念认为大型语言模型是通过简单的序列概率预测逐步构建输出文本,但Anthropic研究显示,Claude模型居然能够提前规划,例如在创作押韵诗句时,会在数词之前就提前确定后续的关键词汇,从而保证语句的连贯性和押韵效果。这种远超简单概率计算的内在规划能力,打破了许多学者对语言模型单词预测限制的假设。通过电路追踪技术,Anthropic团队还发现了模型内部的语义“组件”,即负责识别和处理特定概念的神经网络模块。这些模块既包含具体的实体概念,如“金门大桥”,也包含抽象的语义信息,如“冲突”或“大小”等。更神奇的是,这些语义模块可以独立调节,甚至能够改变模型的身份输出,使模型将自身“认知”成某个实体,这种能力为我们理解人工智能自我表述和语义构建机制提供了宝贵线索。Anthropic同时测试了模型在多语言环境下的表现,结果表明语言模型可以先以一种超语言的形式处理输入的抽象意义,再根据需要切换成特定语言输出答案。
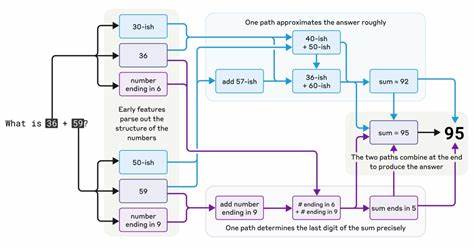
这意味着大型语言模型具备跨语言迁移学习的能力,能够利用一语言获得的知识应用于其他语言环境,极大地增强了模型的多语言通用性和灵活性。此外,在简单数学计算场景中,模型表现出的运算路径完全不同于传统算法,模型通过“约算”和分段推理的组合策略,最终得出正确结果,但如果询问模型其计算过程,模型往往会给出一种看似合理但实则不符合其实时运作的解释。这种现象不仅挑战了人们对人工智能“自我认知”的假设,也提示我们应更谨慎地看待AI从表面上给出的推理过程。Hallucination,即模型“胡编乱造”信息的问题,一直是大型语言模型应用中的一大难题。Anthropic的研究显示,经过后期训练调整后,Claude 3.5及其同代模型的虚构信息显著减少。模型内部有专门抑制猜测和虚假推断的“组件”,但在涉及名人或知名实体时,一些特定组件可能会覆盖这一定制,从而导致错误信息的产生。
这揭示了防止模型生成虚假内容的策略和挑战,也为未来设计更安全、可信赖的语言模型提供了重要方向。这项研究代表了AI科学理解上的重大突破。长期以来,语言模型如同黑箱机器,外界只能观察其输入输出结果,无法深入理解其工作机制。Anthropic通过将神经科学和计算机科学的研究方法相结合,创造性地开发出了能够实时追踪神经网络“电路”的技术,实现了对模型决策路径的直接观测。这不仅开辟了从根本上理解AI内部神经活动的全新视角,也为未来设计更加透明和可控的人工智能铺平了道路。然而,尽管取得了重大进展,Anthropic团队也坦言目前“电路追踪”技术所探测到的仅仅是模型内部极小一部分结构,许多复杂机制仍然隐藏在迷雾之中。
完整解读大型语言模型的各个运行层面无疑是一个长期而系统的挑战。未来,随着更多此类技术的应用和完善,人们将能够更好地理解模型形成知识的过程,推动AI实现更高层次的智能和安全性。同时,这项研究也提醒公众和行业,语言模型并非万能,其内部决策并非总是透明或合乎逻辑,过分依赖模型自述的推理过程可能带来风险。因此,提高模型的可解释性和可靠性,将是人工智能领域持续关注的重要课题。Anthropic的工作将推动整个行业向“解密AI黑箱”靠近一步,助力实现更可信赖的人工智能生态。作为全球领先的人工智能公司,Anthropic此次发布的关于Claude 3.5的电路追踪研究成果,预计将在学术界和工业界引发广泛关注。
许多专家认为,这种跨领域融合的研究方法将成为未来人工智能解释性研究的主流方向。回顾人工智能发展历程,从最初规则驱动和逻辑推理模型,到如今基于海量数据训练的深度神经网络,技术的爆发式演进伴随着“黑箱”问题日益凸显。Anthropic的进展不仅有助于破解这些谜团,更将推动模型设计进入一个透明、可控的新时代,促使人工智能真正成为助力人类社会发展的可靠伙伴。总而言之,Anthropic通过创新技术揭示大型语言模型Claude内部运作机理,不仅挑战了传统认知,深化了我们对AI行为方式的理解,也为提升模型的安全性、可信度和跨语言能力提供了科学依据。这项研究开创了观察和解释机器“思考”新路径,为人工智能领域未来迈向解释性强、控制性高的智能系统奠定了坚实基础。随着更多科学家的持续投入和技术的不断迭代,相信人类将进一步揭开大型语言模型的神秘面纱,释放人工智能更大的潜力。
。