随着人工智能技术的不断进步,代码生成作为自动化编程的重要方向,正吸引着学术界和工业界的广泛关注。传统的代码生成模型大多采用自回归(AR)结构,即通过序列中已有的部分逐步推断下一个Token,这种依赖因果关系的生成方式在许多应用场景中表现出色。然而,近期掩码扩散模型(masked diffusion models,简称dLLMs)的兴起,带来了代码生成领域的全新思考角度和方法路径。作为代表性的工作之一,DiffuCoder以7亿参数规模训练了1300亿代码Token,并通过一系列创新的训练和推理技术,显著提升了生成效果和效率,掀起了代码智能自动化的新篇章。DiffuCoder的核心优势在于其非自回归的生成机制。传统AR模型依赖由左至右的严格顺序生成,一旦前序生成出错,后续Token的准确性难以保障,而扩散模型通过对完整序列的逐步去噪处理,实现了对全局上下文的整体把控,从而具备更强的全局规划与迭代修正能力。
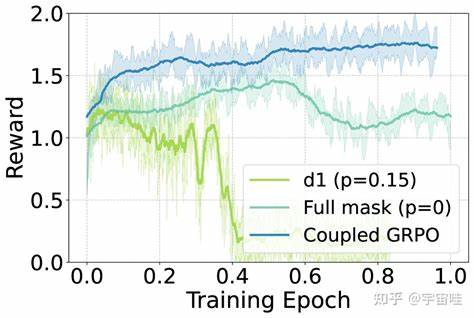
这一特点使得DiffuCoder在代码生成过程中,能够灵活调整“因果性”的程度,而无需依赖半自回归(semi-AR)解码策略,极大地增强了生成的多样性和鲁棒性。有趣的是,DiffuCoder的研究指出,提升采样温度不仅能增加单个Token的多样性,还会改变Token产生的顺序,创造出丰富且多元的搜索空间,这为后续的强化学习尝试提供了肥沃土壤。在训练方法上,DiffuCoder引入了创新性的coupled-GRPO采样方案。这种策略通过构造互补的掩码噪声样本,降低了Token对数似然估计的方差,实现了强化学习训练效率和稳定性的双重提升。通过coupled-GRPO,DiffuCoder在多个代码生成基准测试中表现出了显著提升,例如EvalPlus测试集的表现提升超过4.4%,并且在解码时对自回归偏置的依赖度明显下降,彰显了其纯粹的扩散生成本质和实力。DiffuCoder的出现不仅推动了扩散模型在代码生成领域的应用,还为研究人员揭示了扩散模型与AR模型在内在机制上的重要区别与互补关系。
扩散模型的生成过程允许模型进行多次迭代和全局视角的权衡,使得代码生成更加精准且不易陷入局部最优或生成偏差。此外,强化学习方法的引入为模型的自主优化提供了有力手段,使其在实际编码场景中的表现更加贴近人类编程习惯和需求。展望未来,掩码扩散模型有望整合更多针对代码语法语义的约束和先验知识,进一步提升生成质量与执行效率。多模态融合、交互式编码辅助以及代码调试与自动修复等新兴应用场景,也将推动该技术朝着更加智能化和实用化方向发展。同时,DiffuCoder的研究成果激发了相关开源和产业界的热情,促进了更多基于扩散模型架构的代码生成解决方案不断涌现。总的来说,DiffuCoder标志着掩码扩散模型在代码生成领域迈出了坚实而具有里程碑意义的一步。
它打破了传统AR模型的生成限制,开拓了多样化、全局感知的编码策略,并借助创新的强化学习框架实现了性能的飞跃。随着更多研究者基于该框架进行深入探索,未来代码自动生成的智能水平和实用价值必将得到极大提升,为软件开发的自动化变革带来新的可能性。持续关注DiffuCoder及其相关技术的发展,将帮助开发者和企业抢占技术先机,推动智能编程走入更加广泛和深入的应用时代。