2025年6月1日,知名的聊天应用T3 Chat经历了一场严重的服务中断事件,导致平台用户在数小时内无法正常使用。作为T3 Chat后端服务的重要组成部分,Convex平台在这次事件中起到了关键作用。本次事故的详细调查不仅揭示了系统设计和运行上的不足,还为未来构建更可靠的分布式服务提供了宝贵经验。本文将系统梳理这场故障的始末,探讨Convex如何在高负载条件下出现问题,并为读者深入解析此次事件的根因及改进路径,帮助业界从中吸取教训。首先,有必要对Convex平台的基本架构做一简要介绍。Convex是一款主打反应式设计的后端服务框架,核心优势在于通过WebSocket维护客户端和服务器之间的同步,支持TypeScript服务器端查询函数和数据变更函数。
当数据变更发生时,Convex会自动重新运行相关查询,并推送最新结果至客户端,实现实时的数据更新。与其他同类平台相比,Convex的特点是其高度的可定制性及丰富的运行时调整参数,称为“knobs”,允许开发者根据客户需求微调资源分配、缓存大小和限制阈值等。此次事件中,T3 Chat对Convex的使用方式存在两个显著差异:一是广泛依赖文本搜索功能,二是用户习惯将聊天页面长时间置于后台标签页,从而形成新型的操作模式,带来了此前未遇见的挑战。故障事件的发生过程极具戏剧性。事故初期,即早上6点至7点间,Convex运维工程师注意到部分T3 Chat用户的错误率有所上升,虽一度恢复正常,但此信号预示了潜在隐患。上午9点半左右,问题再次爆发。
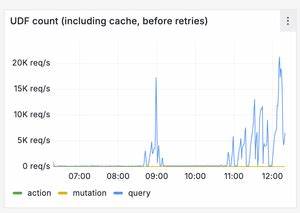
这次随着更多用户醒来使用应用,服务器端检测到待更新订阅数量激增,导致查询失效事件大规模爆发,造成消息订阅队列迅速饱和。由于该队列存在硬编码限制,当负载超过阈值时,服务器开始断开WebSocket连接,客户端陷入连接断开及重连的恶性循环。奇怪的是,查询请求从稳态的每秒几十条,飙升至上千甚至上万条。这种骤增现象促使工程团队启用应急手段,将队列长度限制由1万提升至10万,以期缓解压力。然而,仅有扩大队列容量还不足以稳定服务。重启后的客户端行为暴露出更深层次问题。
Convex客户端的退避机制设计不完善。在连接断开后,客户端会盲目且迅速地重新连接,发起同样导致服务器过载的查询请求,形成所谓的“雷暴效应”,即大量客户端几乎同时发起请求,加剧了服务器的拥堵。为此,团队紧急修改客户端代码,引入指数退避加抖动的策略,减少并发重连冲击,但这个改动在用户端的推广存在时间延迟,旧代码仍在后台标签页不断地请求服务器,进一步加剧了负载。在接下来的数小时内,工程师们进行了大量的性能分析与优化。虽然每一次调整都让系统稍有改善,但始终无法将服务完全拉回稳定状态。更糟糕的是,在某次手动部署更新时,运维团队不慎将T3 Chat的服务部署到了免费账户所用的较低配置硬件上。
这一人为错误导致服务器CPU饱和,严重阻碍了恢复过程。尽管设备硬件规格较低,系统仍奇迹般地维持了一定的响应能力,使得问题定位异常困难。直到中午12点左右,部署回正确资源,服务才真正恢复正常。深入分析曝光出三个核心问题。首要根因是搜索索引压缩算法触发了不必要的查询失效。每当Convex的文本搜索引擎执行索引压缩时,实际并未更改任何数据,但系统却错误地将所有订阅相关的文档标记为失效,导致成千上万的查询被迫重新执行。
对T3 Chat这样拥有大量在线用户同时保持订阅的应用而言,这等于突然激增成百上千倍的查询负载,引爆了服务瓶颈。其次是Convex客户端的重连策略存在缺陷,单纯依靠WebSocket成功连接就重置退避指数,忽略了后端服务器实际健康状态,缺乏合理的负载感知机制。结果就是持续不断地重连请求加重了故障压力。第三个问题则属于运营管理层面,即缺乏对资源部署的严格管控,导致服务运行在不适配的硬件环境中,极大限制了恢复速度。为防止类似事件再度发生,Convex团队制定了明确的改进措施。短期内,将确保所有部署工具严格遵守资源分配规则,同时优化搜索索引功能,使其在无数据变更情况下避免触发查询失效。
此外,更新后的客户端库将引入更智能、更保守的退避策略,并在未来版本中增加针对过载及反复连接的防御能力。中长期目标包括进一步提升订阅引擎的性能,减少索引计算时的资源消耗,建立更为完善的DDOS和搜索场景下的性能测试体系。另一个重点是增强客户端对后台标签页的连接管理,例如通过自动断开长时间不活动的WebSocket连接,降低无谓加压。这次事件无疑为所有依赖Convex或类似实时后端平台的开发者敲响警钟。现代应用在追求即时性与高并发的同时,也必须面对复杂的状态同步与资源限制挑战。系统设计不应仅考虑理想场景,更需充分预见边缘情况和恶劣使用模式。
良好的退避策略、精确的资源监控以及灵活的负载调节是保障服务稳定运行的关键。更重要的是,运维工具和流程应强化对人为失误的防范,确保在紧急修复时仍能保持基本安全网。总而言之,Convex与T3 Chat的这次事故虽是一次痛苦的教训,但其公开透明的分析和迅速的应对措施展现了行业最佳实践。对于技术社区来说,这不仅是对一个产品在高速成长过程中遇到的痛点的深刻剖析,更是一堂关于系统韧性建设的珍贵课程。未来,随着团队持续优化与创新,Convex有望在保证出色性能的同时,提供更为可靠、健壮的服务支撑,助力更多实时应用应对日益复杂的挑战。对于所有关心技术稳定性和用户体验的开发者来说,理解并吸取此次事件的经验,无疑具有非凡的现实意义和指导价值。
。