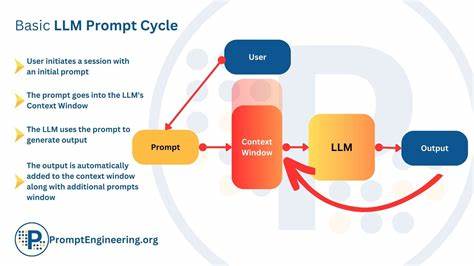
随着大型语言模型(LLM)在各行各业的广泛应用,如何维持它们的上下文一致性和减少记忆漂移问题,成为推动技术进步与实际落地的核心挑战。记忆漂移具体表现为模型在长时间对话中逐渐丧失对先前内容的准确理解,导致回答重复、偏离主题甚至幻觉生成。这不仅影响交互质量,更直接关系用户对AI的信任和依赖。因此,深入研究和解决这一问题尤为重要。 针对这一现象,有研究者提出了一套系统化的协议,旨在通过结构化提示而非单纯依赖巧妙措辞,来降低LLM的记忆漂移。该方案的出发点源于大量用户投诉的收集和分析,汇聚了GitHub、Reddit和Discord等多个社区中真实用户的反馈。
通过梳理这些反馈,研究人员发现了一些典型模式,如上下文丢失、信息重复和主题偏移。 解决方案的核心在于构建一个连续性的框架,该框架综合运用时间戳日志、意图追踪、重置模块和强制格式化等多种手段。时间戳日志能够帮助模型精确回溯对话历史,保证信息的时间顺序不会混淆。意图追踪则确保每轮对话的核心目标被准确捕捉,防止模型偏离用户需求。重置模块设计用于定期“刷新”模型状态,避免潜在记忆累积导致的误差扩散。强制格式化则通过约定好的输入输出规范,减少模型生成结果的多义性和不确定性。
这种结构化的提示体系不仅显著提升了模型答复的稳定性,还优化了用户体验,使对话更连贯、主题更聚焦。然而,作为一种实验性系统,它并非完美无缺。研究者本人也坦言,在最初的分享中忽略了一些关键细节,比如如何动态调整不同用户的意图追踪策略,或者面对复杂多轮对话时如何高效利用时间戳日志的存储和访问效率。 此外,对于不同应用场景和用户群体,记忆漂移的表现形式和严重程度存在较大差异。例如,技术领域的对话往往对精确上下文依赖较高,而娱乐休闲类对话可能对上下文连贯性的要求略低。这意味着应对策略需要具备灵活性和定制化能力,不能简单一刀切。
面对这一挑战,社区层面的反馈和开放合作显得尤为珍贵。通过 GitHub 的开源项目,如名为 MARM-Protocol 的协议实现,开发者可以共享改进思路,测试不同策略,提升整体生态的成熟度。Reddit 等社交媒体上的讨论与建议,也为实践者提供了多元视角和灵感来源。 从技术实现的角度来看,结合强化学习、记忆增强模块和多模态信息融合,有望进一步完善记忆一致性。例如,通过训练模型识别并纠正潜在漂移行为,建立“记忆校对”机制。同时,合理管理上下文缓存大小,动态调整模型对历史信息的权重,都是提升表现的有力途径。
展望未来,随着模型架构和计算资源的持续提升,减少记忆漂移的技术手段必将更加丰富且精准。除了技术层面优化之外,用户体验设计也不可忽视。增加交互的透明度,让用户了解模型当前记忆状态和限制,可以有效降低误解和不满。 总结来看,减少大型语言模型中的记忆漂移是提升其实际应用价值的重要环节。通过结构化提示、意图追踪与合理格式化等技术路径,可以有效缓解漂移现象,提升对话连贯性。同时,持续关注用户反馈、结合多样场景需求,以及推动社区协作与开放创新,都是实现长远改进的关键因素。
面对复杂多变的对话环境,唯有不断迭代与完善,才能让大型语言模型更好地服务于人类社会,体现其真正价值。