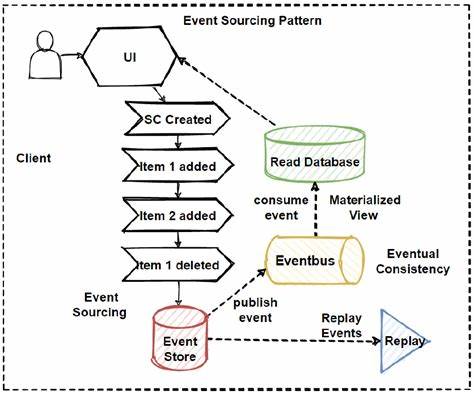
在现代软件架构中,事件溯源(Event-Sourcing)作为一种优秀的设计模式,逐渐受到开发者的广泛关注和应用。它通过保存系统状态的每个变化事件,精确重现数据的变迁过程,打破了传统基于数据库状态的限制,为系统的可追溯性、扩展性和灵活性带来了显著优势。然而,要想真正发挥事件溯源的潜力,正确的设计与实施方法至关重要。 事件溯源的核心理念在于,每一个状态改变都被视为一个不可变的事件序列。这些事件按照时间顺序被保存下来,从而能够通过回放事件还原任意时刻的系统状态。与传统的 CRUD 模型相比,事件溯源不仅保留了最终数据,还系统性地记录了数据变化的过程,这一点对系统审计、调试和数据恢复具有极大价值。
首先,选择合适的事件定义是确保事件溯源有效性的基础。事件应当具有明确的业务含义,尽量反映真实的业务活动,而不是简单的数据操作。例如,在电商系统中,“订单已创建”比“订单数据已插入”更具业务价值。优质的事件命名和清晰的领域边界不仅提升可读性,还方便后续的事件处理和聚合。 其次,事件存储机制的设计直接影响系统的性能和可扩展性。常见的事件存储方式包括关系型数据库、NoSQL 数据库以及专门的事件存储引擎。
选择时应综合考虑数据写入吞吐量、查询效率以及持久化的可靠性。为了更好地满足分布式系统需求,事件存储还应支持横向扩展和高可用性。 事件溯源的另一个关键环节是事件回放和聚合状态的构建。由于系统状态不是直接存储的,而是通过事件回放计算得出,因此需要有效管理事件的累积。当事件数量庞大时,每次回放全部事件将导致性能瓶颈,通常采用快照机制将某些时点的状态保存下来,减少回放事件的数量,提升系统响应速度。 在分布式和微服务架构中,事件溯源同样能够促进服务间的松耦合和灵活交互。
事件作为服务间的异步消息不仅保证数据的一致性,还支持异步处理和复杂事件驱动流程。通过事件总线或消息中间件分发事件,各服务能够独立演化,实现高效的系统扩展与维护。 然而,事件溯源在实际应用中也面临诸多挑战。首先,事件版本管理尤为重要。随着业务逻辑的演变,事件结构可能发生变化,若不妥善处理,旧事件可能无法被正常解析,影响系统稳定性。解决方案包括设计兼容性强的事件格式,增加事件版本信息,并实现事件的转换适配机制。
另外,事件溯源的调试和监控也较传统模型更为复杂。由于系统状态是通过事件流动态生成,开发人员需要具备分析事件序列能力,理解事件间的关系,才能精准定位问题。成熟的可视化工具和事件追踪机制成为辅助开发和运维的重要手段。 安全性方面,事件数据的不可篡改性虽然增强了数据的可信度,但也对数据隐私和合规性提出了挑战。例如,某些敏感信息可能在事件中被永久记录,无法直接删除。对此,可以采用事件加密、访问控制和数据脱敏等技术手段来保障用户隐私和满足法规要求。
最佳的事件溯源实践通常强调与领域驱动设计(DDD)相结合,通过聚合根管理事件的生成与应用,确保业务边界清晰且一致。领域模型的设计不仅决定事件的合理划分,也帮助团队在复杂业务场景中保持代码的高内聚低耦合。 总结来看,正确的事件溯源不仅能够带来系统的透明性和灵活性,还提升了整体架构的健壮性和可维护性。合理设计事件模型、优化存储和回放机制、实现良好的版本管理及安全措施,是成功实施事件溯源的关键所在。不断积累经验,结合具体业务场景灵活调整,方能真正发挥事件溯源技术在现代软件开发中的巨大潜力。