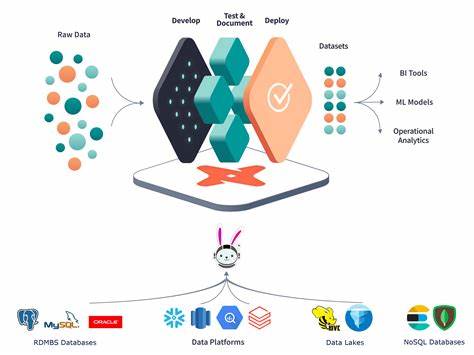
Trino作为一款强大的分布式SQL查询引擎,凭借其灵活性和强大的数据源支持能力,已经成为现代大数据分析场景中的热门工具。它支持跨云端、本地环境、数据湖、传统数据库乃至开源文件格式的统一查询,为企业实现数据的无缝整合和分析提供了极大便利。然而,面对海量数据和复杂查询,数据访问瓶颈问题往往成为制约系统性能的关键因素。了解这些瓶颈产生的根源及其缓解手段,是提升Trino整体性能的关键所在。 Trino的核心优势在于其强大的查询执行能力,它本身不负责数据存储,而是通过连接器架构,连接并查询多种存储系统。这种设计区别于传统数据库管理系统(DBMS)同时承担数据存储和处理的职责。
传统数据库因结构紧密,可以针对数据存储结构进行优化,从而提升性能,比如基于列存储设计的DBMS能够极大地加快特定查询操作,而行存储则适合快速访问整条记录。反观Trino,必须适应各种存储格式,无论是列存储还是行存储,甚至文件格式,因此查询执行引擎需具备更高的通用性,势必引入一定的复杂度和性能折中。 这种复杂性在Trino内部通过连接器(Connector)机制得到巧妙管理。不同连接器负责与具体数据源沟通,传递数据统计信息、数据分区信息和支持权限管理、模式管理等功能。连接器分为特定系统连接器和通用连接器两类,前者针对某种存储系统深入优化,后者支持多种数据源但优化能力有限。性能瓶颈常见于使用通用连接器时,如常见的JDBC连接器,其设计初衷并非处理海量查询结果传输,导致数据以单线程、逐条记录的方式传输,严重限制吞吐量。
JDBC接口效率低下的原因在于其“逐条元组传输”的架构,虽然适用于少量结果集传输,但面对以GB甚至TB级数据量的查询,成为系统性能瓶颈的核心。Trino执行引擎处理的数据往往尚未完成过滤与聚合,意味着必须传输大量原始数据,进一步放大了JDBC协议的瓶颈。此外,数据格式转换过程中,列式存储数据需转换成行格式再通过JDBC传输,失去了原生列存储的优化优势,导致性能大幅下降。 即使增加计算资源,如扩展Trino集群节点,也无法解决JDBC瓶颈带来的单线程传输限制,网络升级同样效果有限,因为真正的瓶颈在接口协议设计本身,而非物理传输路径。实际测试显示,通过JDBC传输数据的速率可能仅为10MB/s,而现代分布式系统本可达到GB/s级别,差距达数百倍甚至数千倍。 针对这一瓶颈,Trino采取了推算和下推策略。
推算器利用数据统计信息来估计不同执行计划的成本,选择最优方案。推下谓词过滤、简单聚合、Top-N以及有限范围的关联操作,减少需要传输的数据量,尽可能将数据筛选和初步处理交由数据存储系统完成,降低Trino与数据源之间的数据交换压力。然而复杂查询、跨多个数据源的关联操作大多无法下推,依然会增加数据传输负担。 特定系统连接器在一定程度上缓解了上述问题。它们能够识别并利用数据源的分区信息,实现多线程并行访问不同数据分区,显著提升传输带宽和并发性能。数据分区基于时间、地理位置或ID等字段,将数据表划分为多个独立片段,使系统能够针对性读取部分数据,避免全表扫从而提高效率。
对应连接器明晰地传递分区元信息给Trino,促使其并行拉取数据,极大缩短查询时延。 此外,系统专属连接器支持更广泛的查询运算下推,减少传输的数据量。例如更多的聚合函数、多条件过滤、部分连接操作都可以直接在数据源执行,大幅减少主系统的计算压力与传输数据量。不同数据库和存储系统的特性决定了连接器的能力,优质连接器能充分发挥数据源内的计算资源,实现性能加速。 当遇到性能瓶颈时,用户首先应明确受影响的数据源和所采用的连接器类型。通常数据湖中存储的开放格式数据访问瓶颈较少,难点主要集中在传统数据库系统。
检查并确认连接器类型和版本非常重要,尝试采用更完善的数据库专属连接器是提升性能的有效途径。像Starburst Enterprise和Galaxy等Trino商业发行版提供了更丰富强大的连接器,支持更加高效的数据访问和处理。 如果数据库未充分实现或暴露分区策略,则可通过数据库自身的分区命令来定义合理的分区结构。细粒度且合理的分区设计极大助力连接器充分利用并行拉取数据。分区应基于查询常用的过滤字段或时间戳,这样能快速缩小查询范围,减少无谓数据传输。 在查询层面,也可以通过增强查询过滤条件,拆分大查询为多个细小查询并行执行,规避单一大查询导致的连接瓶颈。
分批查询策略结合Trino的多连接机制,能显著提升整体吞吐率,缩短响应时间。 如果以上方法无法满足需求,建议将数据周期性地快照导出为开放格式(如Parquet)存储于数据湖环境。Trino对数据湖格式的访问效率极高,极少产生数据访问瓶颈。此项做法需要一定的存储资源和同步机制,但带来的性能提升往往令系统整体运行更为高效稳定。商业版Trino如Starburst甚至提供自动化工具协助数据快照管理,简化生产环境操作。 整体来看,Trino的数据访问性能依赖于连接器的优化能力、数据源的结构设计以及查询策略的合理性。
深刻理解JDBC瓶颈的本质,有针对性地选择高效连接器、优化数据分区和充分利用查询下推,是驱动高性能分布式SQL查询的关键。通过主动规避单线程低吞吐的接口限制,结合并行多线程数据抽取和丰富的查询计算下推,Trino才能充分发挥其跨数据源整合分析的优势,实现TB级甚至PB级数据的快速访问与处理。随着数据规模的持续增长,合理优化这些环节将为企业数据平台带来更具竞争力的性能表现和更敏捷的商业智能分析能力。 未来,随着Trino生态和连接器的不断完善,我们可以期待更多针对具体数据库的深度集成及优化方案,进一步缩小与原生数据库系统的性能差距。同时,人工智能和自动化工具的引入也会促进数据分区设计、查询优化等环节的智能化,为终端用户提供更加方便、高效的分析体验。掌握并应用本文所介绍的核心技术与方案,能够有效避免Trino数据访问瓶颈,推动数据驱动业务快速发展。
。