Newznab API作为Usenet索引领域的标准接口,广泛应用于寻找高质量的二进制内容。对于广大Usenet用户来说,订阅索引器是获取丰富内容的关键步骤。然而,诸多索引器往往对API查询次数有限制,通常设定为每天几千次,旨在防止过度抓取造成服务器性能下降。这种限制虽合理,却给频繁尝鲜或自动化下载流程带来了瓶颈。大量失败尝试后反复发送相同查询,不仅浪费了用户配额,也增大了服务器负载。为此,引入智能缓存机制显得尤为重要。
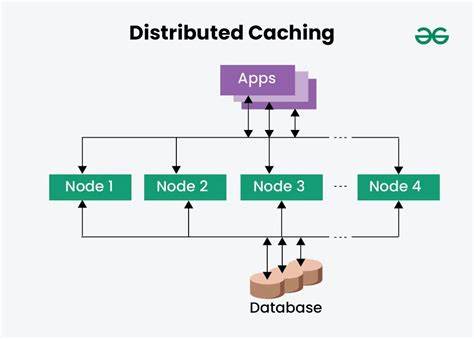
传统的软件大多未内置缓存支持,导致每次搜索都要直接访问远端服务器,尤其是在高延迟或服务器响应缓慢时表现不佳。缓存可以有效减少重复请求,显著提升查询响应速度和稳定性,同时降低向索引器发出的请求数量。Newznab API的一个特殊之处在于其错误响应依然返回HTTP200状态码,错误细节包含在XML响应体内。这一设计增加了缓存判断的复杂度。因传统基于HTTP状态码的缓存策略无法区分成功与失败响应,因此要实现精准缓存就必须解析响应内容,判断是否包含错误信息。Nginx作为高性能的Web服务器,其丰富的模块化架构为缓存提供了良好支持。
更重要的是,借助Lua的灵活编程能力,能够对响应体进行动态解析,实现智能判断缓存条件的功能。实现该缓存策略的第一步是确保Nginx编译时已包含Lua模块,这为后续动态处理奠定基础。配置中通过proxy_cache_path定义缓存存储目录、空间大小和缓存区域,合理设置缓存大小和过期时间保证资源高效利用。针对Newznab API,通常将成功查询结果缓存十分钟,以兼顾数据的新鲜度和访问的连续性。对于不希望缓存的请求,例如利用参数?t=caps进行的连接测试,配置中通过变量控制显式跳过缓存,避免影响测试准确性。核心的智能处理逻辑借助access_by_lua_block,实现对API响应内容的捕获和解析。
如果响应体中检测到<error标签,说明该结果为错误响应,此时设置跳过缓存标志,确保错误信息不会被缓存误用。此机制巧妙地绕过了HTTP状态码无法反映错误的限制,将缓存策略精细化、智能化。配置文件中的proxy_cache_use_stale选项允许在后端错误或超时时依旧使用缓存数据,增强系统的容错能力和用户体验。proxy_cache_lock则防止多请求同时回源,避免瞬间雪崩效应,提升整体性能稳定性。缓存还通过忽略上游Cache-Control、Expires等头部,确保缓存策略不受后端设置干扰,自主控制缓存行为,保持一致性。当缓存生效时,新增的响应头X-Cache-Status清晰指示命中情况,方便运维人员监控和调试。
实际应用中,通过配置Nginx作为本地代理入口,所有索引查询请求先经过缓存层,大幅减少对远端Newznab索引器的直接请求频率。对于用户而言,无感知体验更流畅,响应更快速。对于服务端而言,缓存缓解压力,避免因过载导致的服务拒绝。总的来说,基于Nginx与Lua结合的缓存方案,为Newznab API请求带来了性能与效率的双重提升。它不仅解决了查询次数限制带来的困境,也提升了用户自动化下载工具的表现,降低了系统资源消耗。对于所有依赖Newznab索引的Usenet内容采集者和开发者,这一方法是改善体验的重要参考路径。
展望未来,随着更多智能缓存与负载均衡技术的结合,Usenet生态将迎来更为稳定高效的服务环境。借助开放且灵活的Nginx平台,更多个性化缓存策略与复合逻辑将被开发,不断优化传统索引查询的痛点。对于使用者而言,将索引请求引导至本地缓存层,已经成为必不可少的优化环节。整体来看,缓存Newznab API请求不仅是一项技术提升,更是推动Usenet内容检索和下载体验革新的关键一步。 。