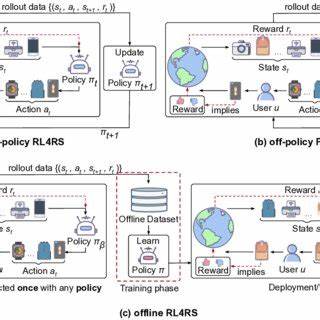
在强化学习领域,策略的优化和数据的有效利用一直是提升智能代理表现的关键问题。随着实际应用对效率和安全性的要求不断提升,离线强化学习(Offline Reinforcement Learning)逐渐成为研究的热点,其中离线策略数据的生成技术——Offpolicy技术,作为实现高效训练的重要手段,受到了越来越多的关注。 Offpolicy的核心理念是,通过利用预先收集的、与当前学习策略不完全相同的历史数据,进行强化学习的策略优化。这种方法打破了传统强化学习需要在线探索的限制,使得训练过程可以在不与真实环境直接交互的前提下完成,大大减少了训练成本和风险。尤其是在自动驾驶、医疗诊断、金融交易等高风险领域,Offpolicy的重要性与价值不可估量。 在生成离线策略数据的过程中,通常需要借助多种数据收集策略,包括历史日志、专家示范数据以及来自多样化策略的采样数据。
通过对这些异构数据的整合,Offpolicy算法能够构建丰富且多样的环境反馈,为学习代理提供广泛的经验支持,提高策略的泛化能力和鲁棒性。值得强调的是,数据的质量与多样性直接影响离线策略的最终效果,因此合理设计采集流程和数据预处理环节极为关键。 另一方面,Offpolicy方法依赖于有效的价值函数估计与策略评估技术。由于训练过程中所用数据与当前策略存在分布差异,如何有效校正这种分布偏移成为研究重点。先进的技术如重要性采样(Importance Sampling)、双重估计(Double Estimation)以及保守策略优化(Conservative Policy Optimization)等被广泛应用于缓解偏差和方差,确保离线训练的稳定性和收敛性。 具体应用方面,Offpolicy技术为强化学习的实际落地提供了强有力的支持。
在机器人控制领域,通过利用离线收集的大量操作数据,能快速提升控制策略的性能而无需频繁物理试验,降低软硬件损耗。在游戏智能、推荐系统等领域,Offpolicy通过历史用户行为数据优化策略,使系统能在无需持续用户参与的情况下实现高效学习和迭代。 此外,结合深度学习的发展,Offpolicy的算法也日益多样化和复杂化。深度Q网络(DQN)、深度确定性策略梯度(DDPG)、灵活的策略表现形式和高维状态空间处理能力推动了离线强化学习效率的提升。现代框架更强调结合模型预测与经验重放技术,通过构建环境模型预测未来状态,进一步拓展了Offpolicy的应用边界。 未来,离线强化学习的研究将聚焦于提升数据利用效率以及设计更为鲁棒的算法以应对现实世界中数据不足及偏差问题。
混合式策略优化、多任务学习与转移学习的结合,有望进一步提升Offpolicy方法对复杂环境的适应能力。同时,安全性约束、可解释性与公平性也逐渐成为算法设计的重要考虑因素,确保强化学习在关键领域的可持续应用。 总之,Offpolicy作为强化学习领域不可或缺的技术路径,通过离线生成和利用策略数据,突破了传统训练模式的限制,推动了智能代理的自主学习与应用革新。持续深化对离线数据生成和策略优化机制的理解,将是未来推动人工智能走向更广泛实用价值的关键力量。