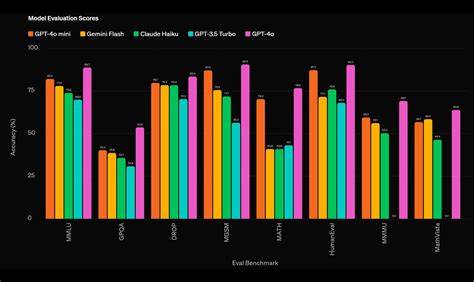
随着计算能力的迅速提升,大规模智能体模型(Agent-Based Models,简称ABM)在经济学、社会科学以及生态系统等多个领域的应用变得日益广泛。这类模型通过模拟大量个体的行为及其相互作用,揭示复杂系统的整体演化规律。然而,由于模型涉及的参数众多,状态空间庞大,如何有效地标定这些模型成为摆在研究者面前的严峻挑战。同时,标定的质量直接关系到模型预测的准确性和实用性。本文将详细介绍大规模智能体模型标定的关键技术与流程,突出基于真实数据的校准思路,探讨最新的泛化变分推断(Generalized Variational Inference, GVI)方法及其在JAX框架中实现的优势。首先,理解智能体模型的结构是掌握标定流程的基础。
智能体模型通常包括大量具有自主决策能力和学习能力的个体,这些个体通过规则或策略与环境及其他智能体互动,最终集体表现出宏观的系统行为。每个智能体的行为参数、环境变量、交互规则等构成了高维参数空间。标定过程的目标在于找到一组参数,使得模型模拟输出能够尽可能贴合观察到的真实数据。现实中,数据往往包含各种噪声和不确定性,这要求标定方法具备良好的鲁棒性与自适应能力。基于贝叶斯框架的变分推断成为实现大规模模型标定的有力工具。该方法通过定义潜变量的先验分布和观测数据的似然函数,转化为计算后验分布的优化问题。
在面对高维复杂模型时,直接计算后验通常不可行,因此采用近似推断策略,如变分推断,以找到在给定变分族内最贴近真实后验的分布。这一过程归结为优化证据下界(ELBO),亦即在数据拟合度和先验约束之间取得平衡。目前的研究表明,经典变分推断在先验分布不准确或模型假设违反时表现有限,泛化变分推断(GVI)则通过替换传统的负对数似然损失函数,引入定制化的损失度量,有效提升了模型对复杂实际问题的适应力。GVI可以通过调节正则化项强度,灵活地控制后验分布与先验分布的偏离程度,从而减弱先验对后验的强制约束,使标定结果更加贴合真实观测。具体实现层面,JAX的自动微分和XLA编译能力为大规模智能体模型的快速标定提供了关键技术支持。JAX采用纯函数式编程风格,使得运行于加速器上的数学计算既简洁又高效。
结合NumPyro概率编程库,可以轻松实现含复杂ODE求解器的贝叶斯模型,完成灵活的变分推断或马尔科夫蒙特卡罗采样。通过JAX的向量化和并行能力,即使面对成千上万个智能体的演化轨迹,模型的训练与验证依旧能够在合理时间内完成。以生态系统中的典型Lotka-Volterra捕食者-猎物模型为例,可见通过定义精确的微分方程系统,并结合带噪声的观测数据,利用GVI对相关速率参数进行推断,能够有效校正模型反映实际动态。标定过程中,首先需设定合理的先验分布,保证参数的物理意义和正定性,同时定义适合的观测噪声模型以模拟现实测量误差。随后,使用自动微分评估损失函数和梯度,配合先进的随机优化算法如Adam进行参数优化,实时调整变分分布。训练完成后,可通过比较模型预测与真实数据、分析后验分布特性、绘制相空间路径图等多种方式,全面评估标定效果。
值得注意的是,虽然GVI能提升标定灵活性,但选择合适的损失函数和正则化系数仍需结合领域知识和实验验证。除生态模型之外,大规模智能体模型广泛应用于经济行为模拟、城市规划、传染病传播等领域。标定技术的普适性使得上述方法可扩展至不同场景,但针对特定应用的定制化调整不可忽视。例如经济模型中,个体决策的异质性可能比生态系统更复杂,模型需融合丰富的行为假设和政策参数,标定需要大规模的异构数据支持。总体来看,大规模智能体模型的标定是一项融合统计学、计算机科学与领域专业知识的跨学科任务。借助先进推断技术如GVI,辅以高性能计算框架JAX,实现稳健且高效的参数估计已成为可能。
今后,随着模型规模进一步扩展和数据种类的多样化,如何设计更有效的近似推断方法、提升标定自动化与智能化水平,将成为研究重点。结语中不难发现,标定是智能体模型实现科学预测和政策探索的基石。通过严谨的模型设计、丰富的数据利用及先进算法支持,科学家和工程师能够准确捕捉系统的内在规律,推动理论与实践的深度融合。未来,结合机器学习、强化学习等新兴技术的标定方法将不断涌现,助力智能体模型发挥更大潜能。 。