在深度学习领域,如何有效地处理离散数据一直是一个难以攻克的挑战。传统的神经网络擅长处理连续数据,通过反向传播算法实现模型参数的优化,但面对离散数据尤其是来自类别分布时,模型训练过程中的梯度计算变得复杂甚至无法实现。Gumbel-Softmax分布作为近期提出的一种创新方法,成功地桥接了离散数据采样和反向传播优化之间的鸿沟,成为许多涉及分类问题和离散变量生成模型中的重要工具。本文将深入解析Gumbel-Softmax分布的基本原理,逐步剖析其背后的技术基础,并探讨其在神经网络训练中的广泛应用。 在介绍Gumbel-Softmax分布之前,须先理解为何对离散分布采样的神经网络训练如此困难。假设一个生成模型需要从一个包含碳、氧、氟三种原子的类别分布中采样节点类型以构建分子图。
神经网络的最终层需要输出代表这些类别的采样结果,这些结果本质上是离散且随机的。然而,离散采样过程本身无法直接计算梯度,因为梯度要求输出对输入参数要求连续且可微,而采样函数的非连续特性导致梯度消失,无法通过反向传播进行模型参数更新。这种局限性严重阻碍了离散变量在深度学习中的应用空间。 为了解决这一难题,Gumbel-Softmax分布结合了两项关键技术:重参数化技巧(Reparameterization Trick)和Gumbel-Max技巧。重参数化技巧最早被用于连续分布,如正态分布的采样。它将采样过程拆分成两个部分,一个是确定性的网络输出部分,另一个是可控的随机噪声部分,从而使整个采样过程能够用可微函数表达,实现梯度的传递。
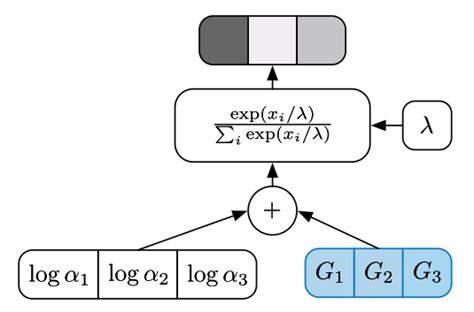
具体来说,采样样本可以表示为均值与中心化随机噪声的线性组合,这种方法消除了梯度阻断的障碍,实现了对采样分布的直接优化。 然而,直接将重参数化技巧应用于离散分布并不可行,因为类别分布本身是非连续的。此时,Gumbel-Max技巧发挥了重要作用。Gumbel-Max技巧通过给类别概率的对数值加上服从Gumbel分布的随机噪声,将类别采样过程转化为最大化操作。简单来说,首先计算每个类别的对数概率,然后加上相应的Gumbel噪声,最终选择最大值对应的类别作为采样结果。Gumbel分布的引入基于其在极值理论中的稳健特性,能够模拟多条概率曲线中最大值的分布,这使得Gumbel-Max技巧稳定且有效地实现了离散采样。
尽管Gumbel-Max技巧有效地完成了离散类别采样,但其内置的最大值操作是不可微的,依旧无法满足反向传播的需求。由此,Gumbel-Softmax分布应运而生,将最大值(argmax)操作用软化版本的softmax函数代替。通过对含Gumbel噪声的类别对数概率应用带温度参数的softmax函数,使得采样结果从纯粹的离散硬采样转变为连续可微的概率分布近似值。这种策略不仅允许梯度信息穿透采样节点,还能通过调节温度参数调控采样分布向真实离散分布的逼近程度。 温度参数在Gumbel-Softmax分布中扮演至关重要的角色,其控制采样概率的平滑程度。当温度较高时,分布趋于均匀,使模型训练更稳定,且梯度方差较低,有利于梯度优化过程的收敛。
随着训练的进行,逐渐降低温度参数,采样结果更趋向于硬分类,即接近于真实的one-hot编码。此种温度退火机制兼顾了训练初期的稳定性与后期模型表达的准确性,显著提升了整体训练效果。 理解了Gumbel-Softmax的基本构建后,其在实际中的应用也日益广泛。它常用于生成模型中,如变分自编码器(VAE)中离散潜变量的采样,使得模型能够有效从离散潜空间学习概率分布。此外,在强化学习和神经结构搜索领域,Gumbel-Softmax帮助构造策略分布,实现动作空间的平滑近似,促进策略网络的高效优化。此外,涉及图神经网络生成的任务中,Gumbel-Softmax也成为节点属性或边属性采样的重要工具。
此外,Gumbel-Softmax满足计算效率的需求。相比于传统的蒙特卡洛方法,Gumbel-Softmax无需在采样时作大量非可微操作,且与求导算法天然兼容,便于在主流深度学习框架中直接实现,无需复杂的自定义梯度计算。这极大地推动了它在工业界和学术界的落地。 尽管如此,Gumbel-Softmax分布也有一定局限。温度参数的调节需要精心设计,否则可能导致梯度方差过大或训练不稳定。此外,由于最终采样是概率分布的近似,模型表达的离散性和精度存在一定折中,需根据具体应用场景仔细调试。
当前研究也在探索进一步改进采样技巧以增强训练稳定性和性能表现。 综上所述,Gumbel-Softmax分布不仅为神经网络引入离散采样和优化提供了实用且高效的解决方案,也为更广泛的领域如自然语言处理、图结构生成和强化学习开辟了新的研究方向。通过桥接离散随机变量和可微优化的技术鸿沟,Gumbel-Softmax显著推动了深度学习模型的多样性和表达能力。随着研究的不断深入,预期其仍将在未来的机器学习应用中扮演关键角色,成为解决离散数据训练难题的利器。