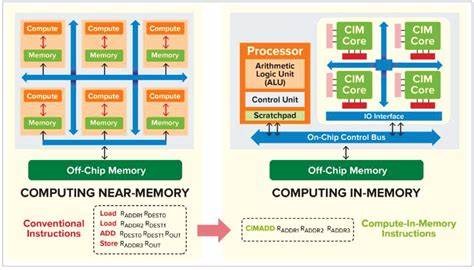
随着深度学习模型规模成倍增长和实时应用需求激增,传统的冯·诺伊曼架构正面临越来越严重的瓶颈。所谓"内存墙"并非抽象概念,而是现实中大量能量和时间被用于在处理器与内存之间搬运数据的具体体现。存内计算(Compute-in-Memory,简称CIM)提出了根本性的变革:把计算尽可能地移到数据所在的位置,从而大幅减少数据移动、降低延迟并显著提升能效。对于以矩阵乘法和乘加(MAC)为核心的神经网络工作负载,存内计算提供了一条具有颠覆性的路线。 存内计算的基本理念极其直接:在内存阵列中或靠近阵列的外围电路中直接完成数学运算,而不是先把数据读出到独立的算术单元再计算。这种方法可以有不同实现范式。
数字存内计算通过改造SRAM或专用的数字单元在位线上实现逻辑和算术操作,保证精度和兼容性;模拟存内计算利用电流求和、电荷共享或电阻阵列的物理叠加特性来并行计算矢量与矩阵乘法,以极高的并行度实现MAC密度。两者之间还有混合信号方案,利用模拟累加生成部分结果再通过ADC转为数字,兼顾能效与精度。 在技术实现上,不同的存储技术各有优势与局限。基于SRAM的存内计算受益于成熟的工艺、高速和可靠性,便于集成到现有AI加速器与SoC中。然而SRAM的单位面积存储密度低、泄漏功耗较高,不利于存储极大模型权重。DRAM在传统意义上不太适合直接做模拟计算,但在近存计算(near-memory processing)和3D堆叠内可通过高带宽内存(HBM)和逻辑层的协同减小数据移动。
更具潜力的是非易失性存储器(eNVM)如阻变存储(ReRAM)、相变存储(PCM)和自旋转移矩阵(MRAM)。这些设备可以在行列交叉阵列中以其物理电阻或电导实现权重存储,电流的并行求和完成矩阵向量乘法,天然契合神经网络的计算模式,并且具有高密度和低静态功耗的优点。 模拟存内计算在能效上优势最大。通过把算术并行化到整个交叉阵列,模拟CIM能在一个时钟周期内对数千、甚至上万条权重执行并加权求和,从而实现极高的TOPS/W(每瓦特万亿次运算)。然而模拟路径也面临精度、噪声、非线性和器件变异等挑战,需要引入校准、容错算法和混合信号补偿。数字存内计算虽然能提供更高的确定性,但在面积和延迟上往往难以追赶模拟实现的极限。
存内计算在AI应用中的价值主要体现在两个方面:能耗和延迟的显著降低,以及系统级带宽瓶颈的缓解。对于大型语言模型(LLM)和Transformer类结构,推理过程中大量时间消耗在权重和激活之间的搬运上。通过把权重常驻在存储阵列并在本地进行乘加计算,存内计算可以将数据传输能耗从整体能耗中剥离出来,带来数十倍到上千倍的能效提升(具体数值受实现技术、工艺节点和网络量化方案影响)。这种能效提升直接转化为更高的吞吐量、更长的边缘部署续航以及更低的云算力成本。 在实际工程中,要把存内计算变成可用、可靠的AI加速器需要解决硬件、软件与系统协同的问题。硬件层面需处理器件非理想性:模拟信号的噪声、ADC/DAC的功耗与面积、非易失性器件的写入能耗与耐久性、以及阵列间的片上互连与热管理。
为降低ADC开销,一些架构采用低精度量化或分段累加,并在软件端做补偿。器件变异和退化问题常通过冗余编码、在线校准与训练感知编程(例如在训练过程中考虑器件噪声)来缓解。 软件层面同样关键。存内计算改变了数据布局和计算流,要求编译器、调度器与神经网络框架理解并高效映射模型到物理阵列。矩阵切分、权重重排、重映射策略以及量化感知训练都是必须优化的环节。为充分发挥CIM的并行优势,模型需要在硬件约束下进行适配,例如更强的稀疏性利用、低精度训练或蒸馏技术。
系统集成层面,3D堆叠与芯片内封装(chiplet)技术为存内计算提供了物理基础。通过将逻辑层直接堆叠在内存上方或将高速互连用于多个存内计算模组之间,能够保证高带宽、低延迟的数据流。HBM等高带宽内存技术也可作为近存计算的后端,结合片上存内单元将"分层内存体系"变得更高效。光子学存算、硅光互连等新兴技术被视为下一阶段的潜在方向,尤其在需要极高带宽与低延迟的云端AI集群中具备吸引力。 存内计算的商业化和产业化正在加速。高校和企业在过去几年内发布了大量基于SRAM、ReRAM等技术的原型芯片,并在图像分类、语音识别和Transformer推理等任务上演示了显著的能效与性能优势。
部分实现已接近工程可用性,而要大规模替代现有GPU/TPU等通用加速器,还需要成熟的软件生态、设计自动化工具和制造良率的提升。 同时,存内计算并非对所有场景都适用。训练阶段对数值精度和可编程性要求高,迄今为止大多数存内计算方案更适合推理或训练中的特定加速子任务。对于需要高精度梯度更新和频繁写入的训练,非易失性器件的有限写耐久和写能耗仍是制约因素。但通过混合架构 - - 把训练关键环节放在数字域或传统加速器上、把权重密集型推理放到CIM阵列中 - - 可以达到工程上的折中与最佳收益。 展望未来,存内计算的发展路径将受到多重因素影响。
器件进步与制造成熟会降低模拟器件噪声与变异,提高可用性。软件与编译器层面的创新将决定CIM能否在更广泛的网络结构上发挥作用。生态系统的建立,包括标准接口、测试基准与工具链,对于推动产业化至关重要。光电混合、量子与其他前沿计算范式的出现也可能与存内计算形成协同,加速AI算力的纵深演进。 对工程师与产品经理而言,理解存内计算的本质与工程权衡是关键。对于边缘设备与对能效敏感的场景,存内计算已经是一个值得优先考虑的架构路径。
而在云端、高性能训练集群中,CIM更可能以协同加速器的形式出现,与GPU/TPU共同构成混合计算平台。投资者与决策者应关注那些既有设备制造能力又有端到端软件支持的团队,因为成功商业化需要软硬件的深度整合和生态建设。 总结来说,存内计算不是单一技术的简单迭代,而是一场从体系结构到器件级别的全栈变革。它以减少数据移动为核心,通过硬件创新与软件协同,目标是为人工智能提供更高的能效、更低的延迟和更经济的规模化能力。在后摩尔时代,这种以内存为中心的计算范式有望成为推动AI落地与普及的重要引擎。对于希望在未来AI浪潮中占据先机的工程团队与企业,及早布局存内计算相关技术、生态与人才将是明智之举。
。