随着大数据技术的迅速发展,数据库引擎不断演进以满足海量数据处理和分析的需求。ClickHouse作为一款高性能的列式数据库,一直受到数据工程师和分析师的广泛关注。2025年7月发布的ClickHouse 25.6版本带来了令人期待的创新功能,其中特别引人注目的便是新推出的CoalescingMergeTree表引擎。此引擎不仅在性能上实现了突破,更满足了在物联网和实时数据场景下对高效存储和快速查询的核心诉求。CoalescingMergeTree引擎的设计初衷是优化处理稀疏更新的场景,它能够智能整合分散的增量数据,减少重复和冗余的行数,同时保留数据的完整性和高保真度。对于需要反复更新但又避免传统整行覆盖的应用场景,CoalescingMergeTree提供了理想的解决方案。
以物联网设备为例,现代电动汽车中的多个子系统会不断发送不同维度的状态数据,如电池电量、定位信息、固件版本和速度传感器数据等。这类数据往往呈现出碎片化、增量更新的特点。传统数据库往往采用UPDATE操作直接覆盖整条记录,这在高吞吐、高并发的IoT场景中效率低下,同时还可能导致锁竞争和数据写入延迟。而ClickHouse鼓励使用具有良好写入性能的追加写入模式,配合CoalescingMergeTree引擎,能够将这些分散的稀疏数据通过后台的合并过程,逐渐融合为每个设备的最新完整状态。这样的机制极大地减少了存储空间占用,同时提升了查询效率。使用CoalescingMergeTree的核心优势在于其独特的合并逻辑。
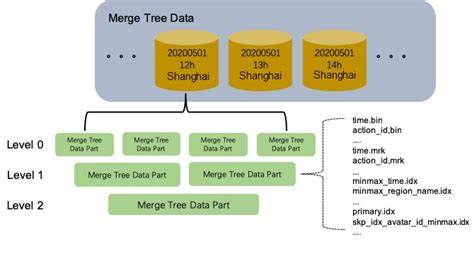
它基于数据的排序键,例如车辆唯一识别码(VIN),在后台的分区合并过程中,从多个写入的数据文件中自动提取并保留每列的最新非空值,放弃过时或空白字段。这种物理上的数据聚合预先生成了“最终态”视图,避免了每次查询都要对海量原始数据进行耗时的聚合计算。与传统MergeTree结合argMax函数按时间戳聚合数据相比,CoalescingMergeTree不仅减少了对CPU资源的消耗,还显著降低了磁盘扫描量,提升了在大规模数据集上的响应速度。值得注意的是,CoalescingMergeTree的“最新”值定义并不依赖于时间戳字段,而是基于数据在存储文件中的写入顺序。这意味着它无需显式维护复杂的时间戳逻辑,采用简单而高效的物理合并手段完成数据整合。不过,为了保证查询时能正确切分更新顺序,仍建议配合明确的时间戳字段,在查询层使用argMax聚合,以实现最佳的数据一致性与时效性。
同时,ClickHouse还提供FINAL关键字,通过强制内存合并所有活动数据文件,可在查询时即时获得完全合并的结果,避免了复杂聚合的计算开销。这对于业务实时性要求高且数据更新频繁的场景尤为适用。推荐的存储模式是将原始完整数据保存在传统的MergeTree表中,同时创建CoalescingMergeTree的物化视图,用于存储合并后的最新状态数据。这样既能保留完整的历史轨迹,便于数据追溯和重放,又能高效支持查询需求,实现数据仓库的性能与完整性双重保障。除了物联网设备状态聚合,CoalescingMergeTree还广泛适用于许多稀疏、增量更新典型场景。用户画像数据的渐进完善、安全审计日志的逐步丰富、ETL流程中维度数据的延迟填充、医生健康记录的持续补充、广告投放数据的实时聚合以及客户服务案件信息的动态更新等,都能通过该引擎极大优化存储效率,降低查询延迟。
整体来看,CoalescingMergeTree引擎充分利用了ClickHouse列式存储和高吞吐写入的优势,将传统高成本的行级更新转变为以追加写入为核心的渐进物理合并,将数据一致性与存储效率双向优化。面对未来万物互联、数据爆炸增长的趋势,这种创新技术无疑为企业构建下一代高性能实时数据库解决方案提供了强有力的工具。ClickHouse 25.6版本的发布,更标志着数据库引擎从单纯关注写入和查询性能,迈向对复杂数据生命周期的智能管理,推动大规模数据处理进入了全新的阶段。对于从事物联网、实时分析、机器学习等领域的技术人员和决策者来说,深刻理解并充分利用CoalescingMergeTree的强大功能,将极大提升数据基础架构的灵活性和响应速度,实现业务价值的飞跃。随着更多应用场景的验证和社区的不断丰富,相信CoalescingMergeTree将在数据存储领域掀起变革浪潮,推动ClickHouse成为全球领先的实时分析数据库。