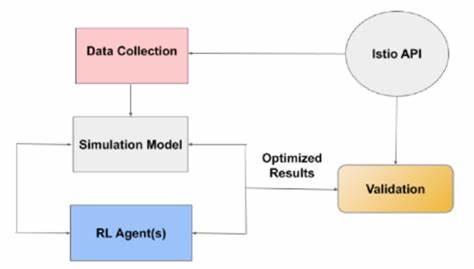
随着网络攻击手段的不断进步和网络防御需求的日益增长,基于人工智能的网络安全技术逐渐成为研究热点。特别是强化学习(Reinforcement Learning,RL)在网络战模拟平台中的应用,为攻防双方智能体提供了自适应学习和决策的能力。然而,尽管强化学习智能体在模拟环境中的表现日益卓越,其行为背后的具体机理及策略选择仍具有较高的黑箱特性,导致研究者与安全专家难以充分理解其成功或失败的原因。深入解析这些智能体行为,对于提升防御策略的有效性和设计更具鲁棒性的系统至关重要。基于此背景,近期对开源深度强化学习智能体在CAGE Challenge 2(仿真网络防御比赛)中的表现进行分析,揭示了获得智能体行为可解释性的有效途径。通过简化复杂的状态及动作空间,结合关键事件的详细追踪,研究团队得以识别出攻击与防御智能体在模拟对抗过程中的细粒度行为及策略动态。
简化状态空间不仅减轻了数据分析负担,也使得行为模式更加清晰。通过对攻击者入侵事件和防御者清理事件的时间序列分析,研究揭示了防御智能体普遍能在一个或两个时间步内清除新发现的受控主机,体现了防御响应的及时性和效率。与此同时,攻击智能体在攻击策略选择上表现出的弱点也得到了体现,例如部分动作显示出40%至99%不具有效果。对动作效果的深入评估帮助团队识别出哪些具体操作对于攻防影响显著,从而提供了优化训练和策略调整的方向。研究还特别关注了诱饵服务(decoy services)对攻击成功率的影响。数据表明,诱饵技术能够有效阻止多达94%的企图直接获取主机特权访问的攻击,从而彰显其在提升网络防御层次中的重要地位。
诱饵通过欺骗和干扰攻击者行为,为防御智能体争取宝贵的响应时间,并增加攻击者的误判几率,成为网络防御体系中的关键组成部分。除此之外,研究团队就CAGE挑战的仿真环境真实度进行了反思和探讨。尽管模拟平台在模拟复杂网络攻击场景中具备优势,但其在真实环境中的移植性和适用性仍有改进空间。针对这些问题,CAGE Challenge 4引入了更为细致和复杂的仿真机制,以更好地对应现实网络中的不确定性和多变性。强化学习智能体在动态网络安全环境中的表现,实际上反映了现代网络战的趋势,即攻守双方都需要快速适应环境变化并调整自身策略。通过对智能体行为的细致观察与数据驱动的分析,安全专家不仅能够提高现有防御系统的智能反应能力,也有助于推动未来智能网络攻防系统的设计理念。
纵观当前研究,基于强化学习的网络战模拟平台正逐步从“黑盒”走向可解释性,增强了其在安全决策支持和策略优化中的实用价值。未来,结合更多具备广泛场景适应性的仿真环境,及更为细粒度的行为分析手段,推动网络攻防智能体的透明化与智能化,将成为网络安全领域的重要发展方向。通过不断深化对智能体策略的理解,研究人员和从业者能够更好地预判攻击趋势,制定有效防御措施,为保护数字空间的安全生态建设贡献力量。总的来看,强化学习赋能的网络战模拟为网络安全研究提供了一个强有力的平台,其智能体行为的深入解析不仅促进了技术进步,也推动了理论与实践的结合,为网络安全领域注入了新的活力和智慧。